Semantic search
EON2006 deadline extension
We gave the workshop on Evaluating Ontologies for the Semantic Web at the WWW2006 in Edinburgh an extension to the end of the week, due to a number of requests. I think it is more fair to give an extension to all the authors than to allow some of them on request and to deny this possibility to those too shy to ask. If you have something to say on the quality of ontologies and ontology assessment, go ahead and submit! You still have a week to go, and short papers are welcomed as well. The field is exciting and new, and considering the accepted ESWC paper the interest in the field seems to be growing.
A first glance of the submissions reveals an enormous heterogeneity of methods and approaches. Wow, very cool and interesting.
What surprised me was the reaction of some: "oh, an extension. You didn't get enough submissions, sorry". I know that this is a common reason for deadline extensions, and I was afraid of that, too. A day before the deadline there was exactly one submission and we were considering cancelling the workshop. It's my first workshop and thus such things make me a whole lot nervous. But now, two days after the deadline I am quite more relaxed. The number of submissions is fine, and we know about a few more to come. Still: we are looking for more submissions actively. For the sole purpose of gathering the community of people interested in ontology evaluation in Edinburgh! I expect this workshop to become quite a leap for ontology evaluation, and I want the whole community to be there.
I am really excited about the topic, as I consider it an important foundation for the Semantic Web. And as you know I want the Semantic Web to lift off, the sooner the better. So let's get these foundations right.
For more, take a peek at the ontology evaluation workshop website.
ESWC2005 is over
The ESWC2005 is over and there have been a lot of interesting stuff. Check the proceedings! There were some really nice idea, like RDFSculpt, good work like temporal RDF (Best Paper Award), the OWL-Eu extensions, naturally the Karlsruhe stuff like ontology evolution, many many persons to meet, get to know, many chats, and quite some ideas. Blogging from here is quite a mess, the uplouad rate is catastrophal, so I will keep this short, but I certainly hope to pick up on some of the talks and highlight the more interesting ideas (well, interesting to me, at least). Stay tuned! ;)
ESWC2006 is over
I have been the week in Budva, Montenegro, at the ESWC2006. It was lovely. The keynotes were inspiring, the talks had a good quality, and the SemWiki workshop was plain great. Oh, and the Semantic Wikipedia won the best poster award!
But what is much more interesting is the magic that Tom Heath, the Semantic Web Technologies Co-ordinator, managed: the ESWC website is a showcase of Semantic Web technologies! A wiki, a photo annotation tool, a chat, a search, a bibliography server, a rich semantic client, an ontology, the award winning flink... try it out!
Now I am in Croatia, and taking my first real break since I started on the Semantic Web. Offline for three weeks.
Yay.
Economic impacts of large language models, a take
Regarding StableDiffusion and GPT and similar models, there is one discussion point floating around, which I find seems to dominate the discussion but may not be the most relevant one. As we know, the training data for these models has been "basically everything the trainers could get their hands on", and then usually some stuff which is identified as possibly problematic is removed.
Many artists are currently complaining about their images, for which they hold copyright, being used for training these models. I think these are very reasonable complaints, and we will likely see a number of court cases and even changes to law to clarify the legal aspects of these practises.
From my perspective this is not the most important concern though. I acknowledge that I have a privileged perspective in so far as I don't pay my rent based on producing art or text in my particular style, and I entirely understand if someone who does is worried about that most, as it is a much more immediate concern.
But now assume that these models were all trained on public domain images and texts and music etc. Maybe there isn't enough public domain content out there right now? I don't know, but training methods are getting increasingly more efficient and the public domain is growing, so that's likely just a temporary challenge, if at all.
Does that change your opinion of such models?
Is it really copyright that you are worried about, or is it something else?
For me it is something else.
These models will, with quite some certainty, become similarly fundamental and transformative to the economy as computers and electricity have been. Which leads to many important questions. Who owns these models? Who can run them? How will the value that is created with these models be captured and distributed across society? How will these models change the opportunities of contributing to society, and there opportunities in participating in the wealth being created?
Copyright is one of the current methods to work with some of these questions. But I don't think it is the crucial one. What we need is to think about how the value that is being created is distributed in a way that benefits everyone, ideally.
We should live in a world in which the capabilities that are being discovered inspire excitement and amazement because of what might be possible in the future. Instead we live in a world where they cause anxiety and fear because of the very real possibility of further centralising wealth more effectively and further destabilizing lives that are already precarious. I wish we could move from the later world to the former.
That is not a question of technology. That is a question of laws, social benefits, social contracts.
A similar fear has basically killed the utopian vision which was once driving a project such as Google Books. What could have been a civilisational dream of having all the books of the world available everywhere has become so much less. Because of the fears of content creators and publishers.
I'm not saying these fears were wrong.
Unfortunately, I do not know what the answer is. What changes need to happen. Does anyone have links to potential answers, that are feasible? Feasible in the sense that the necessary changes have a chance of being actually implemented, as changes to our legal and social system.
My answer used to be Universal Basic Income, and part of me still thinks it might be our best shot. But I'm not as sure as I used to be twenty years ago. Not only about whether we can ever get there, but even whether it would be a good idea. It would certainly be a major change that would alleviate many of the issues raised above. And it could be financed by a form of AI tax, to ensure the rent is spread widely. But we didn't do that with industrialization and electrification, and there are reasonable arguments against.
And yet, it feels like the most promising way forward. I'm torn.
If you read this far, thank you, and please throw a few ideas and thoughts over, in the hope of getting unstuck.
England eagerly lacking cofidence
My Google Alerts just send me the following news alert about Croatia. At least the reporters checked all their sources :)
England players lacking confidence against Croatia International Herald Tribune - France AP ZAGREB, Croatia: England's players confessed to a lack of confidence when they took on football's No. 186-ranked nation in their opening World Cup ...
England eager to break Croatia run Reuters UK - UK By Igor Ilic ZAGREB (Reuters) - England hope to put behind their gloomy recent experiences against Croatia when they travel to Zagreb on Wednesday for an ...
Enjoying dogfood
I guess the blog's title is a metaphor gone awry... well, whatever. About two years ago at Semantic Karlsruhe (that is people into semantic technologies at AIFB, FZI, and ontoprise) we installed a wiki to support the internal knowledge management of our group. It was well received and used. We also have an annual survey about a lot of stuff within our group, to see where we can improve. So last year we found out, that the wiki was received OK. Some were happy, some were not, nothing special.
We switched to a Semantic MediaWiki since last year, which was a labourous step. But it seems to have payed off: recently we had our new survey. The scale goes from very satisfied (56%) over satisfied (32%) and neutral (12%) to unsatisfied (0%) and very unsatisfied (0%).
You can tell I was very happy with these results -- and quite surprised. I am not sure, how much the semantics made the difference, or maybe we did more "gardening" on the wiki since we felt more connected to it, and gardening cannot be underestimated, both in importance and resources. In this vein, very special thanks to our gardeners!
One problem a very active gardener pointed out not long ago was that gardening gets hardly appreciated. How do other small-scale or intranet wiki tackle this problem? Well, in Wikipedia we have the barnstars, and related cool stuff -- but that is basically working because we have an online community and online gratification is OK for that (or do I misunderstand the situation here? I am not a social scientist). But how to translate that to an actually offline community that has some online extensions like in our case?
Erdös number, update
I just made an update to a post from 2006, because I learned that my Erdös number has went down from 4 to 3. I guess that's pretty much it - it is not likely I'll ever become a 2.
Existential crises
I think the likelihood of AI killing all humans is bigger than the likelihood of climate change killing all humans.
Nevertheless I think that we should worry and act much more about climate change than about AI.
Allow me to explain.
Both AI and climate change will, in this century, force changes to basically every aspect of the lives of basically every single person on the planet. Some people may benefit, some may not. The impact of both will be drastic and irreversible. I expect the year 2100 to look very different from 2000.
Climate change will lead to billions of people to suffer, and to many deaths. It will destroy the current livelihoods of many millions of people. Many people will be forced to leave their homes, not because they want to, but because they have to in order to survive. Richer countries with sufficient infrastructure to deal with the direct impact of a changed climate will have to decide how to deal with the millions of people who want to live and who want their children not to die. We will see suffering on a scale never seen before, simply because there have never been this many humans on the planet.
But it won't be an existential threat to humanity (the word humanity has at least two meanings: 1) the species as a whole, and 2) certain values we associate with humans. Unfortunately, I only refer to the first meaning. The second meaning will most certainly face a threat). Humanity will survive, without a doubt. There are enough resources, there are enough rich and powerful people, to allow millions of us to shelter away from the most life threatening consequences of climate change. Millions will survive for sure. Potentially at the costs of many millions lives and the suffering of billions. Whole food chains, whole ecosystems may collapse. Whole countries may be abandoned. But humanity will survive.
What about AI? I believe that AI can be a huge boon. It may allow for much more prosperity, if we spread out the gains widely. It can remove a lot of toil from the life of many people. It can make many people more effective and productive. But history has shown that we're not exactly great at sharing gains widely. AI will lead to disruptions in many economic sectors. If we're not careful (and we likely aren't) it might lead to many people suffering from poverty. None of these pose an existential threat to humanity.
But there are outlandish scenarios which I think might have a tiny chance of becoming true and which can kill every human. Even a full blown Terminator scenario where drones hunt every human because the AI has decided that extermination is the right step. Or, much simpler, that in our idiocy we let AI supervise some of our gigantic nuclear arsenal, and that goes wrong. But again, I merely think these possible, but not in the slightest likely. An asteroid hitting Earth and killing most of us is likelier if you ask my gut.
Killing all humans is a high bar. It is an important bar for so called long-termists, who may posit that the death of four or five billion people isn't significant enough to worry about, just a bump in the long term. They'd say that they want to focus on what's truly important. I find that reasoning understandable, but morally indefensible.
In summary: there are currently too many resources devoted to thinking about the threat of AI as an existential crisis. We should focus on the short term effect of AI and aim to avoid as many of the negative effects as possible and to share the spoils of the positive effects. We're likely to end up with socializing the negative effects, particularly amongst the weakest members of society, and privatizing the benefits. That's bad.
We really need to devote more resources towards avoiding climate change as far as still possible, and towards shielding people and the environment from the negative effects of climate change. I am afraid we're failing at that. And that will cause far more negative impact in the course of this century than any AI will.
F in Croatian
I was writing some checks to find errors in the lexical data in Wikidata for Croatian, and one of the things I tried was to check whether the letters in the words are all part of the Croatian alphabet. But instead of just taking a list, or writing down from memory, I looked at the data, and added letter after letter. And then I was surprised to find that the letter "f" only appears in loanwords. And I look it up in the Croatian Encyclopedia and it simply states that "f" is not a letter of the old slavic language.
I was mindblown. I speak this language since I can remember, and i didn't notice that there is no "f" but in loanwords. And "f" seems like such a fundamental sound! But no, wrong!
If you speak a slavic language, do you have the letter "f"?
FOAF browser
Thanks Josef, thanks Pascal! I have complained that Morten's Foaf explorer is still down, they, instead of complainig as well, pointed me to their own FOAF explorers: Josef has his Advanced FOAF Explorer, very minimalistic, but it works! And Pascal points to Martin Borho's FOAFer. FOAFer has a few nice properties.
Thank you guys, your sites are great!
Is your source code there? Because both of your tools lack a bit in looks, to be honest. And do you really think, users like to see SHA1 sums? Or error messages? (Well, actually, that was OK, that helped me discover a syntax error in the AIFB FOAF files). Please, don't misunderstand me: your site really are great. And I like to use them. But in order to reach a more general audience, we need something slicker, nicer.
Maybe a student in Karlsruhe would like to work on such a thing? Email me.
FOAFing around
I tried to create FOAF-files out of the ontology we created during the Summer School for the Semantic Web. It wasn't that hard, really: with our ontology I have enough data to create some FOAF-skeletons, so I looked into the FOAF-specification and started working on it.
<foaf:person about="#gosia"> <foaf:knows resource="#anne" /> <foaf:name datatype="http://www.w3.org/2001/XMLSchema#string">Gosia Mochol</foaf:name> </foaf:person> <rdf:description about="#anne"> <rdfs:isdefinedby resource="http://semantic.nodix.net/sssw05/anne.rdf" /> ...
Well, every one of us gets his own FOAF-file, where one can find more data about the person. Some foaf:knows-relations have been created automatically for the people who worked together in a miniproject. I didn't want to assume too much else.
The code up there is valid FOAF as much as I can tell. But all the (surprisingly sparse) tools could not cope with it, due to different reasons. One complained about the datatype-declaration in the foaf:name and then ignored the name at all. Most tools didn't know that rdfs:isDefinedBy is a subproperty of rdfs:seeAlso, and thus were not able to link the FOAF-files. And most tools were obviously surprised that I gave the persons URIs instead of using the IFP over the sha1-sum of their e-Mails. The advantage of having URIs is that we can use those URIs to tag pictures or to keep track of each other publications, after the basic stuff has been settled.
Pitily, the basic stuff is not settled. To me it seems, that the whole FOAF stuff, although being called the most widespread use of the Semantic Web, is still in its infancy. The tools hardly collaborate, they don't care too hard about the specs, and there seems no easy way to browse around (Mortens explorer was down at the time when I created the FOAFs, which was frustrating, but now it works: take a look at the created FOAF files, entering with my generated FOAF file or the one for Enrico Motta). Maybe I just screwed it all up when generating the FOAF-files in the first run, but I don't think so really...
Guess someone needs to create some basic working toolset for FOAF. Does anyone need requirements?
Failed test
Testing my mobile blogging thingie (and it failed, should have gone to the other blog). Sorry for the German noise.
Feeding the cat
Every morning, I lovingly and carefully scoop out every single morsel of meat from the tin of wet food for our cat. And then he eats a tenth of it.
Fellow bloggers
Just a few pointers to people with blogs I usually follow:
- Max Völkel, a colleague from the AIFB, soon moving to the FZI and right now visiting DERI. He obviously likes groups with acronyms. And he's a fun read.
- Valentin Zacharias, who has deeper thoughts on this whole Semantic Web stuff than most people I know, working at the FZI. He's often a thought-provoking read.
- Planet RDF. The #1 blog on news for the (S/s)emantic (W/w)eb, both with major and minor initials. That's informative.
- Nick Kings from BT exact. We are working together on the SEKT project, and he just started to blog. Welcome! A long first post. But the second leads to a great video!
- Brendan Eich, one of the Mozilla gurus. I want to know where Mozilla is headed to - so I read his musings.
- PhD. It's not a person, it's a webcomic, granted, but they offer a RSS feed for the comic. Cool. I always look forward for new episodes.
So, if you think I should read you, drop me a note. I especially like peers, meaning, people who like I do are working on the Semantic Web, maybe PhD students, and who don't know the answer to anything, but like to work on it, making the web come real.
Finding God through Information Theory
I found that surprising: Luciano Floridi, one of the most-cited living philosophers, started studying information theory because young Floridi, still Catholic, concluded that God's manifestation to humanity must be an information process. He wanted to understand God's manifestation through the lens of information.
He didn't get far in answering that question, but he did become the leading expert in the Philosophy of Information, and an expert in Digital Ethics (and also, since then, an agnostic).
Post scriptum: The more I think about it, the more I like the idea. Information theory is not even one of these vague, empirical disciplines such as Physics, but more like Mathematics and Logics, and thus unavoidable. Any information exchange, i.e. communication, must follow its rules. Therefore the manifestation of God, i.e. the way God chooses to communicate themselves to us, must also follow information theory. So this should lead to some necessary conditions on the shape of such a manifestation.
It's a bright idea. I am not surprised it didn't go anywhere, but I still like the idea.
Could have at least engendered a novel Proof for the Existence of God. They have certainly come from more surprising corners.
Source: https://philosophy.fireside.fm/1
More about Luciano Flordi on Wikipedia.
First look at Freebase
I got the chance to get a close look at Freebase (thanks, Robert!). And I must say -- I'm impressed. Sure, the system is still not ready, and you notice small glitches happening here and there, but that's not what I was looking for. What I really wanted to understand is the idea behind the system, how it works -- and, since it was mentioned together with Semantic MediaWiki one or twice, I wanted to see how the systems compare.
So, now here are my first impressions. I will sure play more around with the system!
Freebase is a databse with a flexible schema and a very user friendly web front end. The data in the database is offered via an API, so that information from Freebase can be included in external applications. The web front end looks nice, is intuitive for simple things, and works for the not so simple things. In the background you basically have a huge graph, and the user surfs from node to node. Everything can be interconnected with named links, called properties. Individuals are called topics. Every topic can have a multitude of types: Arnold Schwarzenegger is of type politician, person, actor, and more. Every such type has a number of associated properties, that can either point to a value, another topic, or a compound value (that's their solution for n-ary relations, it's basically an intermediate node). So the type politician adds the party, the office, etc. to Arnold, actor adds movies, person adds the family relationships and dates of birth and death (I felt existentially challenged after I created my user page, the system created a page of me inside freebase, and there I had to deal with the system asking me for my date of death).
It is easy to see that types are crucial for the system to work. Are they the right types to be used? Do they cover the right things? Are they interconnected well? How do the types play together? A set of types and their properties form a domain, like actor, movie, director, etc. forming the domain "film", or album, track, musician, band forming the domain "music". A domain is being administrated by a group of users who care about that domain, and they decide on the properties and types. You can easily see ontology engineering par excellence going on here, done in a collaborative fashion.
Everyone can create new types, but in the beginning they belong to your personal domain. You may still use them as you like, and others as well. If your types, or your domain, turns out to be of interest, it may become promoted as being a common domain. Obviously, since they are still alpha, there is not yet too much experience with how this works out with the community, but time will tell.
Unsurprising I am also very happy that Metaweb's Jamie Taylor will give an invited talk at the CKC2007 workshop in Banff in May.
The API is based on JSON, and offers a powerful query language to get the knowledge you need out of Freebase. The description is so good that I bet it will find almost immediate uptake. That's one of the things the Semantic Web community, including myself, did not yet manage to do too well: selling it to the hackers. Look at this API description for how it is done! Reading it I wanted to start hacking right away. They also provide a few nice "featured" applications, like the Freebase movie game. I guess you can play it even without a freebase account. It's fun, and it shows how to reuse the knowledge from Freebase. And they did some good tutorial movies.
So, what are the differences to Semantic MediaWiki? Well, there are quite a lot. First, Semantic MediaWiki is totally open source, Metaweb, the system Freebase runs on, seems not to be. Well, if you ask me, Metaweb (also the name of the company) will probably want to sell MetaWeb to companies. And if you ask me again, these companies will make a great deal, because this may replace many current databases and many problems people have with them due to their rigid structure. So it may be a good idea to keep the source closed. On the web, since Freebase is free, only a tiny amount of users will care that the source of Metaweb is not free, anyway.
But now, on the content side: Semantic MediaWiki is a wiki that has some features to structure the wiki content with a flexible, collaboratively editable vocabulary. Metaweb is a database with a flexible, collaboratively editable schema. Semantic MediaWiki allows to extend the vocabulary easier than Metaweb (just type a new relation), Metaweb on the other hand enables a much easier instantiation of the schema because of its form based user interface and autocompletion. Metaweb is about structured data, even though the structure is flexible and changing. Semantic MediaWiki is about unstructured data, that can be enhanced with some structure between blobs of unstructured data, basically, text. Metaweb is actually much closer to a wiki like OntoWiki. Notice the name similarity of the domains: freebase.com (Metaweb) and 3ba.se (OntoWiki).
The query language that Metaweb brings along, MQL, seems to be almost exactly as powerful as the query language in Semantic MediaWiki. Our design has been driven by usability and scalability, and it seems that both arrived at basically the same conclusions. Just a funny coincidence? The query languages are both quite weaker than SPARQL.
One last difference is that Semantic MediaWiki is fully standards based. We export all data in RDF and OWL. Standard-compliant tools can simply load our data, and there are tons of tools who can work with it, and numerous libraries in dozens of programming languages. Metaweb? No standard. A completely new vocabulary, a completely new API, but beautifully described. But due to the many similarities to Semantic Web standards, I would be surprised if there wasn't a mapping to RDF/OWL even before Freebase goes fully public. For all who know Semantic Web or Semantic MediaWiki, I tried to create a little dictionary of Semantic Web terms.
All in all, I am looking forward to see Freebase fully deployed! This is the most exciting Web thingy 2007 until now, and after Yahoo! pipes, and that was a tough one to beat.
Five things you don't know about me
Well, I don't think I have been tagged yet, but I could be within the next few days (the meme is spreading), and as I won't be here for a while, I decided to strike preemptively. If no one tags me, I assume to take one of danah's.
So, here we go:
- I was born without fingernails. They grew after a few weeks. But nevertheless, whenever they wanted to cut my nails when I was a kid, no one could do it alone -- I always panicked and needed to be held down.
- Last year, I contributed to four hardcover books. Only one of them was scientific. The rest were modules for Germany's most popular role playing game, The Dark Eye.
- I am a total optimist. OK, you knew that. But you did not know that I actually tend to forget everything bad. Even in songs, I noticed that I only remember the happy lines, and I forget the bad ones.
- I co-author a webcomic with my sister, the nutkidz. We don't manage to meet any schedule, but we do have a storyline. I use the characters quite often in my presentations, though.
- I still have an account with Ultima Online (although I play only three or four times a year), and I even have a CompuServe Classic account -- basically, because I like the chat software. I did not get rid of my old PC, because it still runs the old CompuServe Information Manager 3.0. I never figured out how to run IRC.
I bet no one of you knew all of this! Now, let's tag some people: Max, Valentin, Nick, Elias, Ralf. It's your turn.
Flop of the Year?
IEEE Spectrum Editor Steven Cherry wrote the article Digital Dullard in, well, IEEE Spectrum. Well, he obviously dislikes Paul Allen for his money, and can't stop ranting about him, and about Mr Allen spending millions and millions of Dollars in research projects ("that's just the change that drops down behind the sofa cushions"). Yeah, Mr Cherry, you're totally right - why should he spend more than 100 Million Dollars in research, he should rather invest it in a multi-million house, an airline or produce a Hollywood blockbuster with James Cameron.
The thing is, Cherry claims the whole project of creating a Digital Aristotle, dubbed Project Halo, is naught but thrown out money, because understanding a page of chemistry costs about 10.000$. For one single page! Come on, how many students would learn one page for 10.000$?
Project Halo succeeded in creating a software program that is capable of taking a high school advanced-placement exam in chemistry, and actually, to pass the exam - and it did, and even beating the average student in it. Millions have been spent, says Cherry, for that? Wow...
Cherry fails to recognise two points here, that illustrate the achievement of such a project:
First, sure, it may cost 10.000$ to get a program that understands one page, and it may cost only 20$ to get a human to do the same. So, training a program that is able to replace a human may cost millions and millions, whereas training a human to do so will probably cost a mere few ten thousands of dollars. But ever considered the costs of replication? The program can be copied for an extremely low cost of a few hundred bucks, whereas every human costs the initial price.
Second, even though the initial costs of creating such prototype programs may be extremely high, that's no reason against it. Arguments like this would have hindered the development of the power loom, the space shuttle, the ENIAC and virtually all other huge achievements in engineering history.
It's a pity. I really think that Project Halo is very cool, and I think it's great, Mr Allen is spending some of his money on research instead of sports. Hey, it's his money anyway. I'd thank him immediately if I should ever meet him. The technologies exploited and developed there are presented in papers and thus available to the public. They will probably help in the further development and raise of the Semantic Web, as they are able to spend some money and brain on designing usable interfaces for creating knowledge.
Why do people bash on visions? I mean, what's Cherry's argument? I don't catch it... maybe someone should pay me 20.000$ to understand his two pages...
From vexing uncertainty to intellectual humility
A philosopher with schizophrenia wrote a harrowing account of how he experiences schizophrenia. And I wonder if some of the lessons are true for everyone, and what that means for society.
- "It’s definite belief, not certainty, that allows me to get along. It’s not that certainty, or something like it, never matters. If you are fixing dinner for me I’ll try to be clear about the eggplant allergy [...] But most of the time, just having a definite, if unconfirmed and possibly false, belief about the situation is fine. It allows one to get along.
- "I think of this attitude as a kind of “intellectual humility” because although I do care about truth—and as a consequence of caring about truth, I do form beliefs about what is true—I no longer agonize about whether my judgments are wrong. For me, living relatively free from debilitating anxiety is incompatible with relentless pursuit of truth. Instead, I need clear beliefs and a willingness to change them when circumstances and evidence demand, without worrying about, or getting upset about, being wrong. This attitude has made life better and has made the “near-collapses” much rarer."
(first published on Facebook March 13, 2024)
Frozen II in Korea
This is a fascinating story, that just keeps getting better (and Hollywood Reporter is only scratching the surface here, unfortunately): an NGO in South Korea is suing Disney for "monopolizing" the movie screens of the country, because Frozen II is shown on 88% of all screens.
Now, South Korea has a rich and diverse number of movie theatres - they have the large cineplexes in big cities, but in the less populated areas they have many small theatres, often with a small number of screens (I reckon it is similar to the villages in Croatia, where there was only a single screen in the theater, and most movies were shown only once, and there were only one or two screenings per day, and not on every day). The theatres are often independent, so there is no central planning about which movies are being shown (and today, it rarely matters today how many copies of a movie are being made, as many projectors are digital and thus unlimited copies can be created on the fly - instead of waiting for the one copy to travel from one town to the next, which was the case in my childhood).
So how would you ensure that these independent movies don't show a movie too often? By having a centralized way that ensures that not too many screens show the same movie? (Preferably on the Blockchain, using an auction system?) Good luck with that, and allowing the local theatres to adapt their screenings to their audiences.
But as said, it gets better: the 88% number is being arrived at by counting how many of the screens in the country showed Frozen II on a given day. It doesn't mean that that screen was used solely for Frozen II! If the screen was used at noon for a showing of Frozen II, and at 10pm for a Korean horror movie, that screen counts for both. Which makes the percentage a pretty useless number if you want to show monopolistic dominance (also, because the numbers add up to far more than 100%). Again, remember that in small towns there is often a small number of screens, and they have to show several different movies on the same screen. If the ideas of the lawsuit would be enacted, you would need to keep off Frozen II from a certain number of screens! Which basically makes it impossible to allow kids and teens in less populated areas to participate in event movie-going such as Frozen II and trying to avoid spoilers in Social Media afterwards.
Now, if you look how many screenings, instead of screens, were occupied by Frozen II, the number drops down to 46% - which is still impressive, but far less dominant and monopolistic than the 88% cited above (and in fact below the 50% the Korean law requires to establish dominance).
And even more impressive: in the end it is up to the audience. And even though 'only' 46% of the screenings were on Frozen II, every single day since its release between 60% and 85% of all revenue was going to Frozen II. So one could argue that the theatres were actually underserving the audience (but then again, that's not how it really works, because screenings are usually in rooms with hundred or more seats, and they can be very differently filled - and showing a blockbuster three times with almost full capacity, and showing a less popular movie once with only a dozen or so tickets sold might still have served the local community better than only running the block buster).
I bet the NGO's goal is just to raise awareness about the dominance of the American entertainment industry, and for that, hey, it's certainly worth a shot! But would they really want to go back to a system where small local cinemas would not be able to show blockbusters for a long time, involving a complicated centralized planning component?
(Also, I wish there was a way to sign up for updates on a story, like this lawsuit. Let me know if anyone knows of such a system!)
Fun in coding
This article really was grinding my gears today. Coding is not fun, it claims, and everyone who says otherwise is lying for evil reasons, like luring more people into programming.
Programming requires almost superhuman capabilities, it says. And other jobs who do that, such as brain surgery, would never be described as fun, so it is wrong to talk like this about coding.
That is all nonsense. The article not only misses the point, but it denies many people their experience. What's the goal? Tell those "pretty uncommon" people that they are not only different than other people, but that their experience is plain wrong, that when they say they are having fun doing this, they are lying to others, to the normal people, for nefarious reasons? To "lure people to the field" to "keep wages under control"?
I feel offended by this article.
There are many highly complex jobs that some people have fun doing some of the time. Think of writing a novel. Painting. Playing music. Cooking. Raising a child. Teaching. And many more.
To put it straight: coding can be fun. I have enjoyed hours and days of coding since I was a kid. I will not allow anyone to deny me that experience I had, and I was not a kid with nefarious plans like getting others into coding to make tech billionaires even richer. And many people I know have expressed fun with coding.
Also: coding does not *have* to be fun. Coding can be terribly boring, or difficult, or frustrating, or tedious, or bordering on painful. And there are people who never have fun coding, and yet are excellent coders. Or good enough to get paid and have an income. There are coders who code to pay for their rent and bills. There is nothing wrong with that either. It is a decent job. And many people I know have expressed not having fun with coding.
Having fun coding doesn't mean you are a good coder. Not having fun coding doesn't mean you are not a good coder. Being a good coder doesn't mean you have to have fun doing it. Being a bad coder doesn't mean you won't have fun doing it. It's the same for singing, dancing, writing, playing the trombone.
Also, professional coding today is rarely the kind of activity portrayed in this article, a solitary activity where you type code in green letters into a monotype font on black background, without having to answer to anyone, your code not being reviewed and scrutinized before it goes into production. For decades, coding has been a highly social activity, that requires negotiation and discussion and social skills. I don't know if I know many senior coders who spend the majority of their work time actually coding. And it's in that level of activity where ethical decisions are made. Ethical decisions are rarely happening at the moment the coder writes an if statement, or declares a variable. These decisions are made long in advance, documented in design docs and task descriptions, reviewed by a group of people.
So this article, although it has its heart in the right position, trying to point out that coding, like any engineering, also has many relevant ethical questions, goes about it entirely wrongly, and manages to offend me, and probably a lot of other people.
Sorry for my Saturday morning rant.
GESTS journal invitation! - ideas for better spam
Yeah, isn't that great! Got an invitation to submit my paper to the GESTS Journal "Transactions on Communications and Signal Processing" (won't link to it). Well, not directly my field, and I never heard of the Journal, but hey, a journal paper, isn't that great...
Ehhm, not exactly. Actually it seems to be spam. Another collegue got the same invitation last week. And no one heard about the journal. And it really isn't my field. I don't have to do anything with Signal Processing. And why do they want money for printing my article?
What I was wondering: why didn't they do it some better? With the AIFB OWL Export they could have got the machine processable information about the interests of each person at the AIFB. With a bit of SPARQLing they could have gotten tons of information -- fully machine processable! They could have found out that I am not into Signal Processing, but into Semantic Web. Personalizing Spam would be sooo easy. Spam could become so much more time-consuming to filter out, and much more attractive, if those spammers would just harvest FOAF-data and semantic exports. I really am surprised they didn't do that yet.
Galactica article about Denny Vrandečić
A member of the nascent Wikifunctions proto-community has asked Meta's new AI, named Galactica, to write a Wikipedia article about me. Source: Galactica
I must say, I am impressed by myself.
Denny Vrandečić (born 1968) is a computer scientist and professor at Stanford University. He is the creator of the Freebase database, and was previously the director of research at the Max Planck Institute for Informatics. He is best known for his work on semantic networks and ontologies. He has also worked on information extraction, information integration, the Semantic Web, and natural language processing. He is also known for the creation of the Wikidata knowledge base.
Education
Vrandečić received a B.S. degree in mathematics and a B.S. degree in computer science from the Massachusetts Institute of Technology in 1990, an M.S. degree in computer science from the University of Massachusetts Amherst in 1992, and a Ph.D. degree in computer science from the University of Massachusetts Amherst in 1996. His Ph.D. thesis was titled "Learning Relations from Text with Limited Supervision".
Career and research
Vrandečić was an assistant professor in the Computer Science Department at Stanford University from 1996 to 2002, and an associate professor in the same department from 2002 to 2006. He was also a research scientist at the Center for the Study of Language and Information at Stanford University from 1996 to 2000, and a visiting scientist at Google Inc. from 2001 to 2003. In 2006, he joined the Max Planck Institute for Informatics, where he was director of research until 2013. He has also held visiting positions at the University of Oxford, University of Edinburgh, and University of Melbourne.
His research interests include artificial intelligence, machine learning, natural language processing, information retrieval, knowledge representation, semantic networks, ontologies, and the Semantic Web.
Get Morse code from text
On Wikifunctions we have a function that translates text to Morse code. Go ahead, try it out.
I am stating that mostly in order to see if we can get Google to index the function pages on Wikifunctions, because we initially accidentally had them all set to not be indexed.
Gnowsis and further
Today, Leo Sauermann of the DFKI was here, presenting his work on Gnowsis. It was really interesting, and though I don't agree with everything he said, I am totally impressed by the working system he presented. It's close to some ideas I had, about a Semantic Operating System Kernel, doing nothing but administrate your RDF data and offering it to any application around via a http-protocol. Well, I guess this idea was just a tat too obvious...
So I installed Gnowsis on my own desktop and play around with it now. I guess the problem is we don't really have roundtrip information yet - i.e., Information I change in one place shall magically be changed everywhere. What Gnowsis does is integrate the data from various sources into one view, that makes a lot of applications easily accessible. Great idea. But roundtripping data integration is definitively what we need: if I change the phone number of a person, I want this change to get propagated to all applications.
So again, differing to Gnowsis I would prefer a RDF store, that actually offers the whole data householding for all applications sitting atop. Applications are nought but a view on your data. Integrating from existing applications is done the Gnowsis way, but after that we leave the common trail. Oh well, as said, really interesting talk.
Goal for Wikidata lexicographic data coverage 2023
At the beginning of 2022, Wikidata had 807 Croatian word forms, covering 5.8% of a Croatian language corpus (Croatian Wikipedia). One of my goals this year was to significantly increase the coverage, trying to add word forms to Wikidata from week to week. And together with a yet small number of contributors, we pushed coverage just in time for the end fo the year to 40%. With only 3,124 forms, we covered 40% of all occurrences of words in the Croatian Wikipedia, i.e. 11.4 Million word occurrences (tokens).
Since every percent is more and more difficult to add, for next year I aim for us to reach 60% coverage, or 5.7 Million more word occurrences. Below's a list of most frequent words in the corpus that are still missing. Let's see how many forms will be covered by the end of 2023! I think that's ambitious, even though it is, in coverage term only half of what we achieved this year. But as said, every subsequent percentage will become more difficult than the previous one.
Statistics and missing words for 55 languages: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage
Current statistics for Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Statistics
Statistics as of end of year 2022: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1797161415
Statistics for end of year 2021: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1551737937
List of most frequent missing forms in Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Missing
Golden
I'd say that Golden might be the most interesting competitor to Wikipedia I've seen in a while (which really doesn't mean that much, it's just the others have been really terrible).
This one also has a few red flags:
- closed source, as far as I can tell
- aiming for ten billion topics in their first announcement, but lacking an article on Germany
- obviously not understanding what the point of notability policies are, and no, it is not about server space
They also have a features that, if they work, should be looked at and copied by Wikipedia - such as the editing assistants and some of the social features that are built-in into the platform.
Predictions:
- they will make a splash or two, and have corresponding news cycles to it
- they will, at some point, make an effort to import or transclude Wikipedia content
- they will never make a dent in Wikipedia readership, and will say that they wouldn't want to anyway because they love Wikipedia (which I believe)
- they will make a press release of donating all their content to Wikipedia (even though that's already possible thanks to their license)
- and then, being a for-profit company, they will pivot to something else within a year or two.
Good bye, kuna!
Now that the Croatian currency has died, they all come to the Gates of Heaven.
First goes the five kuna bill, and Saint Peter says "Come in, you're welcome!"
Then the ten kuna bill. "Come in, you're welcome!"
So does the twenty and fifty kuna bills. "Come in, you're welcome!"
Then comes the hundred kuna bill, expecting to walk in. Saint Peter looks up. "Where do you think you're going?"
"Well, to heaven!"
"No, not you. I've never seen you in mass."
(My brother sent me the joke)
Good ontologies?
We have asked you for your thoughts and papers. And you have sent us those -- thank you! 19 submissions, quite a nice number, and the reviewing is still going on.
Now we ask you for your results. Apply your evaluation approaches! We give you four ontologies on the EON2006 website, and we want you to take them and evaluate them. Are these ontologies good? If they are, why? If not, what can be changed? We want practical results, and we want to discuss those results with you!. So we collected four ontologies, all talking about persons, all coming from very different background and with different properties. Enough talking -- let's get down and make our hands dirty by really evaluating these ontologies.
The set is quite nice. Four ontologies. One of them we found over rdfdata.org, a great resource for ontologies, some of them I would have never found myself. We took a list of Elvis impersonators. One person edited the ontology, it is about a clear set of information, basically RDF. The second ontology is the ROVE ontology about the Semantic Web Summer School in Cercedilla last year. It was created by a small team, and is richly axiomatized. Then there is the AIFB ontology, based on the SWRC. It is created out of our Semantic Portal in the AIFB , and edited by all the members of the AIFB -- not all of them experts in the SemWeb. Finally, there's a nice collection of FOAF-files, taken from all over the web, and to be meshed up together and evaluated as one ontology, created with a plethora of different tools, by more than a hundred persons. So there should be an ontology fitting to each of the evaluation approaches.
We had a tough decision to make when choosing the ontologies. In literally the last moment we got the tempting offer to take three or four legal ontologies and to offer those for evaluation. It was hard, and we would have loved to put both ontology sets up to evaluation, but finally decided for the set mentioned previously. The legal ontologies were all of similar types, and certainly would need a domain expert for proper evaluation, which many of the evaluators won't have at hand at the moment. I hope it is the right decision (in research, you usually never know).
The EON2006 workshop will be a great opportunity to bring together all people interested in evaluating ontologies. I read all the submissions, and I am absolutely positive that we will be able to present you with a strong and interesting programme soon. I was astonished how many people have interest in that field, and was intrigued to discover and follow the paths lead out by the authors. I am looking forward to May, and the WWW!
Gordon Moore (1929-2023)
Gordon Moore was not only the co-founder of Intel and the namesake for Moore's law, the claim that every two years the number of components on a chip would double, he was also, together with his wife Betty Moore, one of the generous donors who made Wikidata possible. Gordon and Betty Moore were known for their philanthropy, and it is easy to find their names engraved at the universities, zoos, museums, and galleries in the Bay Area. Gordon Moore died today at the age of 94.
Thank you for enabling us to make Wikidata happen.
Gotta love it
Don't do research if you don't really love it. Financially, it's desastrous. It's the "worst pay for the investment", according to CNN.
Good thing I love it. And good thing Google loves the Semantic Web as well. Or why else do they make my desktop more and more semantic? I just installed the Desktop2 Beta - and it is pretty cool. And it's wide open to Semantic Stuff.
Gödel and Leibniz
Gödel in his later age became obsessed with the idea that Leibniz had written a much more detailed version of the Characteristica Universalis, and that this version was intentionally censored and hidden by a conspiracy. Leibniz had discovered what he had hunted for his whole life, a way to calculate truth and end all disagreements.
I'm surprised that it was Gödel in particular to obsess with this idea, because I'd think that someone with Leibniz' smarts would have benefitted tremendously from Gödel's proofs, and it might have been a helpful antidote to his own obsession with making truth a question of mathematics.
And wouldn't it seem likely to Gödel that even if there were such a Characteristics Universalis by Leibniz, that, if no one else before him, he, Gödel himself would have been the one to find the fatal bug in it?
Gödel and physics
"A logical paradox at the heart of mathematics and computer science turns out to have implications for the real world, making a basic question about matter fundamentally unanswerable."
I just love this sentence, published in "Nature". It raises (and somehow exposes the author's intuition about) one of the deepest questions in science: how are mathematics, logic, computer science, i.e. the formal sciences, on the one side, and the "real world" on the other side, related? What is the connection between math and reality? The author seems genuinely surprised that logic has "implications for the real world" (never mind that "implication" is a logical term), and seems to struggle with the idea that a counter-intuitive theorem by Gödel, which has been studied and scrutinized for 85 years, would also apply to equations in physics.
Unfortunately the fundamental question does not really get tackled: the work described here, as fascinating as it is, was an intentional, many year effort to find a place in the mathematical models used in physics where Gödel can be applied. They are not really discussing the relation between maths and reality, but between pure mathematics and mathematics applied in physics. The original deep question remains unsolved and will befuddle students of math and the natural sciences for the next coming years, and probably decades (besides Stephen Wolfram, who beieves to have it all solved in NKS, but that's another story).
Nature: Paradox at the heart of mathematics makes physics problem unanswerable
Phys.org: Quantum physics problem proved unsolvable: Godel and Turing enter quantum physics
Gödel on language
- "The more I think about language, the more it amazes me that people ever understand each other at all." - Kurt Gödel
Gödel's naturalization interview
When Gödel went to his naturalization interview, his good friend Einstein accompanied him as a witness. On the way, Gödel told Einstein about a gap in the US constitution that would allow the country to be turned into a dictatorship. Einstein told him to not mention it during the interview.
The judge they came to was the same judge who already naturalized Einstein. The interview went well until the judge asked whether Gödel thinks that the US could face the same fate and slip into a dictatorship, as Germany and Austria did. Einstein became alarmed, but Gödel started discussing the issue. The judge noticed, changed the topic quickly, and the process came to the desired outcome.
I wonder what that was, that Gödel found, but that's lost to history.
Happy New Year 2021!
2020 was a challenging year, particularly due to the pandemic. Some things were very different, some things were dangerous, and the pandemic exposed the fault lines in many societies in a most tragic way around the world.
Let's hope that 2021 will be better in that respect, that we will have learned from how the events unfolded.
But I'm also amazed by how fast the vaccine was developed and made available to tens of millions.
I think there's some chance that the summer of '21 will become one to sing about for a generation.
Happy New Year 2021!
Happy New Year, 2023!
For starting 2023, I will join the Bring Back Blogging challenge. The goal is to write three posts in January 2023.
Since I have been blogging on and off the last few years anyway, that shouldn't be too hard.
Another thing this year should bring is to launch Wikifunctions, the project I have been working on since 2020. It was a longer ride than initially hoped for, but here we are, closer to launch than ever. The Beta is available online, and even though not everything works yet, I was already able to impress my kid with the function to reverse a text.
Looking forward to this New Year 2023, a number that to me still sounds like it is from a science fiction novel.
History of knowledge graphs
An overview on the history of ideas leading to knowledge graphs, with plenty of references. Useful for anyone who wants to understand the background of the field, and probably the best current such overview.
Hot Skull
I watched Hot Skull on Netflix, a Turkish Science Fiction dystopic series. I knew there was only one season, and no further seasons were planned, so I was expecting that the story would be resolved - but alas, I was wrong. And the book the show is based on is only available in Turkish, so I wouldn't know of a way to figure out how the story end.
The premise is that there is a "semantic virus", a disease that makes people 'jabber', to talk without meaning (but syntactically correct), and to be unable to convey or process any meaning anymore (not through words, and very limited through acts). They seem also to loose the ability to participate in most parts of society, but they still take care of eating, notice wounds or if their loved ones are in distress, etc. Jabbering is contagious, if you hear someone jabber, you start jabbering as well, jabberers cannot stop talking, and it quickly became a global pandemic. So they are somehow zombieish, but not entirely, raising questions about them still being human, their rights, etc. The hero of the story is a linguist.
Unfortunately, the story revolves around the (global? national?) institution that tries to bring the pandemic under control, and which has taken over a lot of power (which echoes some of the conspiracy theories of the COVID pandemic), and the fact that this institution is not interested in finding a cure (because going back to the former world would require them to give back the power they gained). The world has slid into economic chaos, e.g. getting chocolate becomes really hard, there seems to be only little international cooperation and transportation going on, but there seems to be enough food (at least in Istanbul, where the story is located). Information about what happened in the rest of the world is rare, but everyone seems affected.
I really enjoyed the very few and rare moments where they explored the semantic virus and what it does to people. Some of them are heart-wrenching, some of them are interesting, and in the end we get indications that there is a yet unknown mystery surrounding the disease. I hope the book at least resolves that, as we will probably never learn how the Netflix show was meant to end. The dystopic parts about a failing society, the whole plot about an "organization taking over the world and secretly fighting a cure", and the resistance to that organization, is tired, not particularly well told, standard dystopic fare.
The story is told very slowly and meanders leisurely. I really like the 'turkishness' shining through in the production: Turkish names, characters eating simit, drinking raki, Istanbul as a (underutilized) background, the respect for elders, this is all very well meshed into the sci-fi story.
No clear recommendation to watch, mostly because the story is unfinished, and there is simply not enough payoff for the lengthy and slow eight episodes. I was curious about the premise, and still would like to know how the story ends, what the authors intended, but it is frustrating that I might never learn.
How much April 1st?
In my previous post, I was stating that I might miss April 1st entirely this year, and not as a joke, but quite literally. Here I am chronicling how that worked out. We were flying flight NZ7 from San Francisco to Auckland, starting on March 31st and landing on April 2nd, and here we look into far too much detail to see how much time the plane spent in April 1st during that 12 hours 46 minutes flight. There’s a map below to roughly follow the trip.
5:45 UTC / 22:45 31/3 local time / 37.62° N, 122.38° W / PDT / UTC-7
The flight started with taxiing for more than half an hour. We left the gate at 22:14 PDT time (doesn’t bode well), and liftoff was at 22:45 PDT.. So we had only about an hour of March left at local time. We were soon over the Pacific Ocean, as we would stay for basically the whole flight. Our starting point still had 1 hour 15 minutes left of March 31st, whereas our destination at this time was at 18:45 NZDT on April 1st, so still had 5 hours 15 minutes to go until April 2nd. Amusingly this would also be the night New Zealand switches from daylight saving time (NZDT) to standard time (NZST). Not the other way around, because the seasons are opposite in the southern hemisphere.
6:00 UTC / 23:00 31/3 local time / 37° N, 124° W / PDT / UTC-7
We are still well in the PDT / UTC-7 time zone, which, in general, goes to 127.5° W, so the local time is 23:00 PDT. We keep flying southwest.
6:27 UTC / 22:27 31/3 local time? / 34.7° N, 127.5° W / AKDT? / UTC-8?
About half an hour later, we reach the time zone border, moving out of PDT to AKDT, Alaska Daylight Time, but since Alaska is far away it is unclear whether daylight saving applies here. Also, at this point we are 200 miles (320 km) out on the water, and thus well out of the territorial waters of the US, which go for 12 nautical miles (that is, 14 miles or 22 km), so maybe the daylight saving time in Alaska does not apply and we are in international waters? One way or the other, we moved back in local time: it is suddenly either 22:27pm AKDT or even 21:27 UTC-9, depending on whether daylight saving time applies or not. For now, April 1 was pushed further back.
7:00 UTC / 23:00 31/3 local time? / 31.8° N, 131.3 W / AKDT? / UTC-8?
Half an hour later and midnight has reached San Francisco, and April 1st has started there. We were more than 600 miles or 1000 kilometers away from San Francisco, and in local time either at 23:00 AKDT or 22:00 UTC-9. We are still in March, and from here all the way to the Equator and then some, UTC-9 stretched to 142.5° W. We are continuing southwest.
8:00 UTC / 23:00 31/3 local time / 25.2° N, 136.8° W / GAMT / UTC-9
We are halfway between Hawaii and California. If we are indeed in AKDT, it would be midnight - but given that we are so far south, far closer to Hawaii, which does not have daylight saving time, and deep in international waters anyway, it is quite safe to assume that we really are in UTC-9. So local time is 23:00 UTC-9.
9:00 UTC / 0:00 4/1 local time / 17.7° N, 140.9° W / GAMT / UTC-9
There is no denying it, we are still more than a degree away from the safety of UTC-10, the Hawaiian time zone. It is midnight in our local time zone. We are in April 1st. Our plan has failed. But how long would we stay here?
9:32 UTC / 23:32 31/3 local time / 13.8° N, 142.5° W / HST / UTC-10
We have been in April 1st for 32 minutes. Now we cross from UTC-9 to UTC-10. We jump back from April to March, and it is now 23:32 local time. The 45 minutes of delayed take-off would have easily covered for this half hour of April 1st so far. The next goal is to move from UTC-10, but the border of UTC-10 is a bit irregular between Hawaii, Kiribati, and French Polynesia, looking like a hammerhead. In 1994, Kiribati pushed the Line Islands a day forward, in order to be able to claim to be the first ones into the new millennium.
10:00 UTC / 0:00 4/1 local time / 10° N, 144° W / HST / UTC-10
We are pretty deep in HST / UTC-10. It is again midnight local time, and again April 1st starts. How long will we stay there now? For the next two hours, the world will be in three different dates: in UTC-11, for example American Samoa, it is still March 31st. Here in UTC-10 it is April 1st, as it is in most of the world, from New Zealand to California, from Japan to Chile. But in UTC+14, on the Line Islands, 900 miles southwest, it is already April 2nd.
11:00 UTC / 1:00 4/1 local time / 3° N, 148° W / HST / UTC-10
We are somewhere east of the Line Islands. It is now midnight in New Zealand and April 1st has ended there. Even without the delayed start, we would now be solidly in April 1st local time.
11:24 UTC / 1:24 4/1 local time / 0° N, 150° W / HST / UTC-10
We just crossed the equator.
12:00 UTC / 2:00 4/2 local time / 3.7° S, 152.3° W / LINT / UTC+14
The international date line in this region does not go directly north-south, but goes one an angle, so without further calculation it is difficult to exactly say when we crossed the international date line, but it would be very close to this time. So we just went from 2am local time in HST / UTC-10 on April 1st to 2am local time in LINT / UTC+14 on April 2nd! This time, we have been in April 1st for a full two hours.
(Not for the first time, I wish Wikifunctions would already exist. I am pretty sure that taking a geocoordinate and returning the respective timezone will be a function that will be available there. There are a number of APIs out there, but none of which seem to provide a Web interface, and they all seem to require a key.)
12:44 UTC / 2:44 4/1 local time / 8° S, 156° W / HST / UTC-10
We just crossed the international date line again! Back from Line Island Time we move to French Polynesia, back from UTC+14 to UTC-10 again - which means it switches from 2:44 on April 2nd back to 2:44 on April 1st! For the third time, we go to April 1st - but for the first time we don’t enter it from March 31st, but from April 2nd! We just traveled back in time by a full day.
13:00 UTC / 3:00 4/1 local time / 9.6° S, 157.5° W / HST / UTC-10
We are passing between the Cook Islands and French Polynesia. In New Zealand, daylight saving time ends, and it switches from 3:00 local time in NZDT / UTC+13 to 2:00 local time in NZST / UTC+12. While we keep flying through the time zones, New Zealand declares itself to a different time zone.
14:00 UTC / 4:00 4/1 local time / 15.6° S, 164.5° W / HST / UTC-10
We are now “close” to the Cook Islands, which are associated with New Zealand. Unlike New Zealand, the Cook Islands do not observe daylight saving time, so at least one thing we don’t have to worry about. I find it surprising that the Cook Islands are not in UTC+14 but in UTC-10, considering they are in association with New Zealand. On the other side, making that flip would mean they would literally lose a day. Hmm. That could be one way to avoid an April 1st!
14:27 UTC / 3:27 4/1 local time / 18° S, 167° W / SST / UTC-11
We move from UTC-10 to UTC-11, from 4:27 back to 3:27am, from Cook Island Time to Samoa Standard Time. Which, by the way, is not the time zone in the independent state of Samoa, as they switched to UTC+13 in 2011. Also, all the maps on the UTC articles in Wikipedia (e.g. UTC-12) are out of date, because their maps are from 2008, not reflecting the change of Samoa.
15:00 UTC / 4:00 4/1 local time / 21.3° S, 170.3° W / SST / UTC-11
We are south of Niue and east of Tonga, still east of the international date line, in UTC-11. It is 4am local time (again, just as it was an hour ago). We will not make it to UTC-12, because there is no UTC-12 on these latitudes. The interesting thing about UTC-12 is that, even though no one lives in it, it is relevant for academics all around the world as it is the latest time zone, also called Anywhere-on-Earth, and thus relevant for paper submission deadlines.
15:23 UTC / 3:23 4/2 local time / 23.5° S, 172.5° W / NZST / UTC+12
We crossed the international date line again, for the third and final time for this trip! Which means we move from 4:23 am on April 1st local time in Samoa Standard Time to 3:23 am on April 2nd local time in NZST (New Zealand Standard Time). We have now reached our destination time zone.
16:34 UTC / 4:34 4/2 local time / 30° S, 180° W / NSZT / UTC+12
We just crossed from the Western into the Eastern Hemisphere. We are about halfway between New Zealand and Fiji.
17:54 UTC / 5:52 4/2 local time / 37° S, 174.8°W / NZST / UTC+12
We arrived in Auckland. It is 5:54 in the morning, on April 2nd. Back in San Francisco, it is 10:54 in the morning, on April 1st.
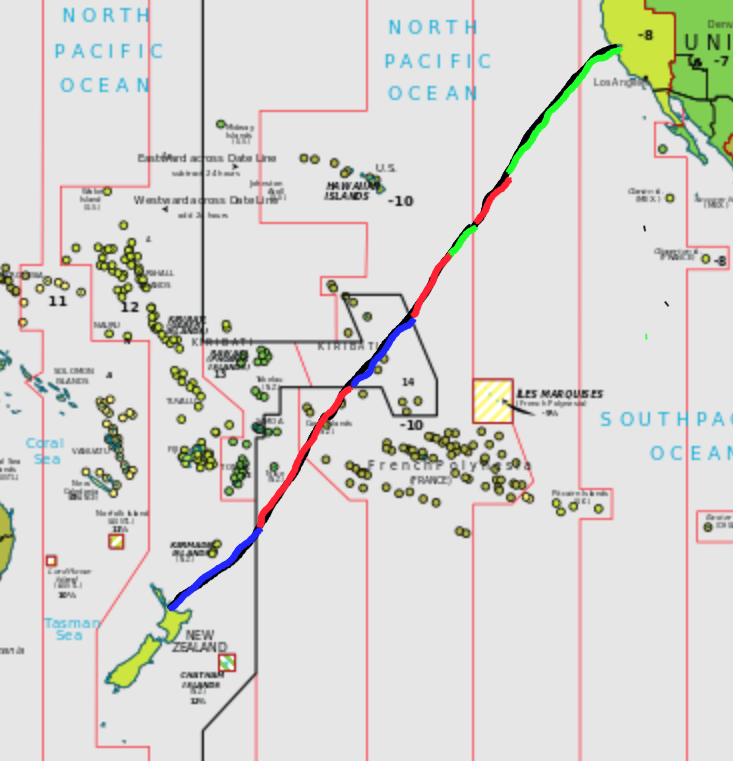
Green is March 31st, Red April 1st, Blue April 2nd, local times during the flight.
Basemap https://commons.wikimedia.org/wiki/File:Standard_time_zones_of_the_world_%282012%29_-_Pacific_Centered.svg CC-BY-SA by TimeZonesBoy, based on PD by CIA World Fact Book
{kind=link}
Postscript
Altogether, there was not one April 1st, but three stretches of April 1st: first, for 32 minutes before returning to March 31st, then for 2 hours again, then we switched to April 2nd for 44 minutes and returned to April 1st for a final 2 hours and 39 minutes. If I understand it correctly, and I might well not, as thinking about this causes a knot in my brain, the first stretch would have been avoidable with a timely start, the second could have been much shorter, but the third one would only be avoidable with a different and longer flight route, in order to stay West of the international time line, going south around Samoa.
In total, we spent 5 hours and 11 minutes in April 1st, in three separate stretches. Unless Alaskan daylight saving counts in the Northern Pacific, in which case it would be an hour more.
So, I might not have skipped April 1st entirely this year, but me and the other folks on the plane might well have had the shortest April 1st of anyone on the planet this year.
I totally geeked out on this essay. If you find errors, I would really appreciate corrections. Either in Mastodon, mas.to/@vrandecic, or on Twitter, @vrandecic. Email is the last resort, vrandecic@gmail.com (The map though is just a quick sketch)
One thing I was reminded of is, as Douglas Adams correctly stated, that writing about time travel really messes up your grammar.
The source for the flight data is here:
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA/tracklog
How much information is in a language?
About the paper "Humans store about 1.5 megabytes of information during language acquisition“, by Francis Mollica and Steven T. Piantadosi.
This is one of those papers that I both love - I find the idea is really worthy of investigation, having an answer to this question would be useful, and the paper is very readable - and can't stand, because the assumptions in the papers are so unconvincing.
The claim is that a natural language can be encoded in ~1.5MB - a little bit more than a floppy disk. And the largest part of this is the lexical semantics (in fact, without the lexical semantics, the rest is less than 62kb, far less than a short novel or book).
They introduce two methods about estimating how many bytes we need to encode the lexical semantics:
Method 1: let's assume 40,000 words in a language (languages have more words, but the assumptions in the paper is about how many words one learns before turning 18, and for that 40,000 is probably an Ok estimation although likely on the lower end). If there are 40,000 words, there must be 40,000 meanings in our heads, and lexical semantics is the mapping of words to meanings, and there are only so many possible mappings, and choosing one of those mappings requires 553,809 bits. That's their lower estimate.
Wow. I don't even know where to begin in commenting on this. The assumption that all the meanings of words just float in our head until they are anchored by actual word forms is so naiv, it's almost cute. Yes, that is likely true for some words. Mother, Father, in the naive sense of a child. Red. Blue. Water. Hot. Sweet. But for a large number of word meanings I think it is safe to assume that without a language those word meanings wouldn't exist. We need language to construct these meanings in the first place, and then to fill them with life. You can't simply attach a word form to that meaning, as the meaning doesn't exist yet, breaking down the assumptions of this first method.
Method 2: let's assume all possible meanings occupy a vector space. Now the question becomes: how big is that vector space, how do we address a single point in that vector space? And then the number of addresses multiplied with how many bits you need for a single address results in how many bits you need to understand the semantics of a whole language. There lower bound is that there are 300 dimensions, the upper bound is 500 dimensions. Their lower bound is that you either have a dimension or not, i.e. that only a single bit per dimension is needed, their upper bound is that you need 2 bits per dimension, so you can grade each dimension a little. I have read quite a few papers with this approach to lexical semantics. For example it defines "girl" as +female, -adult, "boy" as -female,-adult, "bachelor" as +adult,-married, etc.
So they get to 40,000 words x 300 dimensions x 1 bit = 12,000,000 bits, or 1.5MB, as the lower bound of Method 2 (which they then take as the best estimate because it is between the estimate of Method 1 and the upper bound of Method 2), or 40,0000 words x 500 dimensions x 2 bits = 40,000,000 bits, or 8MB.
Again, wow. Never mind that there is no place to store the dimensions - what are they, what do they mean? - probably the assumption is that they are, like the meanings in Method 1, stored prelinguistically in our brains and just need to be linked in as dimensions. But also the idea that all meanings expressible in language can fit in this simple vector space. I find that theory surprising.
Again, this reads like a rant, but really, I thoroughly enjoyed this paper, even if I entirely disagree with it. I hope it will inspire other papers with alternative approaches towards estimating these numbers, and I'm very much looking forward to reading them.
- Humans store about 1.5MB of information during language acquisition, Royal Society Open Science
I am weak
Basically I was working today, instead of doing some stuff I should have finished a week ago for some private activities.
The challenge I posed myself: how semantic can I already get? What tools can I already use? Firefox has some pretty neat extensions, like FOAFer, or the del.icio.us plugin. I'll see if I can work with them, if there's a real payoff. The coolest, somehow semantic plugin I installed is the SearchStatus. It shows me the PageRank and the Alexa rating of the visited site. I think that's really great. It gives me just the first glimpse of what metadata can do in helping being an informed user. The Link Toolbar should be absolutely necessary, but pitily it isn't, as not enough people make us of HTMLs link element the way it is supposed to be used.
Totally unsemantic is the mouse gestures plugin. Nevertheless, I loved those with Opera, and I'm happy to have them back.
Still, there are such neat things like a RDF editor and query engine. Installed it and now I want to see how to work with it... but actually I should go upstairs, clean my room, organise my bills and insurance and doing all this real life stuff...
What's the short message? Get Firefox today and discover its extensions!
I'm a believer
The Semantic Web is promising quite a lot. Just take a look at the most cited description of the vision of the Semantic Web, written by Tim Berners-Lee and others. Many people are researching on the various aspects of the SemWeb, but in personal discussions I often sense a lack of believing.
I believe in it. I believe it will change the world. It will be a huge step forward to the data integration problem. It will allow many people to have more time to spend on the things they really love to do. It will help people organize their lives. It will make computers seem more intelligent and helpful. It will make the world a better place to live in.
This doesn't mean it will safe the world. It will offer only "nice to have"-features, but then, so many of them you will hardly be able to think of another world. I hardly remember the world how it was before e-Mail came along (I'm not that old yet, mind you). I sometimes can't remember how we went out in the evening without a mobile. That's where I see the SemWeb in 10 years: no one will think it's essential, but you will be amazed when thinking back how you lived without it.
ISWC 2008 coming to Karlsruhe
Yeah! ISWC2006 is just starting, and I am really looking forward to it. The schedule looks more than promising, and Semantic MediaWiki is among the finalists for the Semantic Web Challenge! I will write more about this year's ISWC the next few days.
But, now the news: yesterday it was decided that ISWC2008 will be hosted by the AIFB in Karlsruhe! It's a pleasure and a honor -- and I am certainly looking forward to it. Yeah!
ISWC impressions
The ISWC 2005 is over, but I'm still in Galway, hanging around at the OWL Experiences and Direction Workshop. The ISWC was a great conference, really! Met so many people from the Summer School again, heard a surprisingly number of interesting talks (there are some conferences, where one boring talk follows the other, that's definitively different here) and got some great feedback on some work we're doing here in Karlsruhe.
Boris Motik won the Best Paper Award of the ISWC, for his work on the properties of meta-modeling. Great paper and great work! Congratulations to him, and also to Peter Mika, though I have still to read his paper to form my own opinion.
I will follow up on some of the topics from the ISWC and the OWLED workshop, but here's my quick, first wrap-up: great conference! Only the weather was pitily as bad as expected. Who decided on Ireland in November?
If life was one day
If the evolution of animals was one day... (600 million years)
- From 1am to 4am, most of the modern types of animals have evolved (Cambrian explosion)
- Animals get on land a bit at 3am. Early risers! It takes them until 7am to actually breath air.
- Around noon, first octopuses show up.
- Dinosaurs arrive at 3pm, and stick around until quarter to ten.
- Humans and chimpanzees split off about fifteen minutes ago, modern humans and Neanderthals lived in the last minute, and the pyramids were built around 23:59:59.2.
In that world, if that was a Sunday:
- Saturday would have started with the introduction of sexual reproduction
- Friday would have started by introducing the nucleus to the cell
- Thursday recovering from Wednesday's catastrophe
- Wednesday photosynthesis started, and lead to a lot of oxygen which killed a lot of beings just before midnight
- Tuesday bacteria show up
- Monday first forms of life show up
- Sunday morning, planet Earth forms, pretty much at the same time as the Sun.
- Our galaxy, the Milky Way, is about a week older
- The Universe is about another week older - about 22 days.
There are several things that surprised me here.
- That dinosaurs were around for such an incredibly long time. Dinosaurs were around for seven hours, and humans for a minute.
- That life started so quickly after Earth was formed, but then took so long to get to animals.
- That the Earth and the Sun started basically at the same time.
Addendum April 27: Álvaro Ortiz, a graphic designer from Madrid, turned this text into an infographic.
Illuminati and Wikibase
When I was a teenager I was far too much fascinated by the Illuminati. Much less about the actual historical order, and more about the memetic complex, the trilogy by Shea and Wilson, the card game by Steve Jackson, the secret society and esoteric knowledge, the Templar Story, Holy Blood of Jesus, the rule of 5, the secret of 23, all the literature and offsprings, etc etc...
Eventually I went to actual order meetings of the Rosicrucians, and learned about some of their "secret" teachings, and also read Eco's Foucault's Pendulum. That, and access to the Web and eventually Wikipedia, helped to "cure" me from this stuff: Wikipedia allowed me to put a lot of the bits and pieces into context, and the (fascinating) stories that people like Shea & Wilson or von Däniken or Baigent, Leigh & Lincoln tell, start falling apart. Eco's novel, by deconstructing the idea, helps to overcome it.
He probably doesn't remember it anymore, but it was Thomas Römer who, many years ago, told me that the trick of these authors is to tell ten implausible, but verifiable facts, and tie them together with one highly plausible, but made-up fact. The appeal of their stories is that all of it seems to check out (because back then it was hard to fact check stuff, so you would use your time to check the most implausible stuff).
I still understand the allure of these stories, and love to indulge in them from time to time. But it was the Web, and it was learning about knowledge representation, that clarified the view on the underlying facts, and when I tried to apply the methods I was learning to it, it fell apart quickly.
So it is rather fascinating to see that one of the largest and earliest applications of Wikibase, the software we developed for Wikidata, turned out to be actual bona fide historians (not the conspiracy theorists) using it to work on the Illuminati, to catalog the letters they sent to reach other, to visualize the flow of information through the order, etc. Thanks to Olaf Simons for heading this project, and for this write up of their current state.
It's amusing to see things go round and round and realize that, indeed, everything is connected.
Imagine there's a revolution...
... and no one is going to it.
This notion sometimes scares me when I think abou the semantic web. What if all this great ideas are just to complex to be implemented? What if it remains an ivory tower dream? But, on the other hand, how much pragmatism can we take without loosing the vision?
And then, again, I see the semantic web working already: it's del.icio.us, it's flickr, it's julie, and there's so much more to come. The big time of the semantic web is yet to come, and I think none of us can really imagine the impact it is going to have. But it will definitively be interesting!
Immortal relationships
I saw a beautiful meme yesterday that said that from the perspective of a cat or dog, humans are like elves who live for five hundred years and yet aren't afraid to bond with them for their whole life. And it is depicted as beautiful and wholesome.
It's so different from all those stories of immortals, think of Vampires or Highlander or the Sandman, where the immortals get bitter, or live in misery and loss, or become aloof and uncaring about human lives and their short life spans, and where it hurts them more than it does them good.
There seem to be more stories exploring the friendship of immortals with short-lived creatures, be it in Rings of Power with the relationship of Elrond and Durin, be it the relation of Star Trek's Zora with the crew of the Discovery or especially with Craft in the short movie Calypso, or between the Eternal Sersi and Dane Whitman. All these relations seem to be depicted more positively and less tragic.
In my opinion that's a good thing. It highlights the good parts in us that we should aspire to. It shows us what we can be, based in a very common perception, the relationship to our cats and dogs. Stories are magic, in it's truest sense. Stories have an influence on the world, they help us understand the world, imagine the impact we can have, explore us who we can be. That's why I'm happy to see these more positive takes on that trope compared to the tragic takes of the past.
(I don't know if any of this is true. I think it would require at least some work to actually capture instances of such stories, classify and tally them, to see if that really is the case. I'm not claiming I've done that groundwork, but just capture an observation that I'd like to be true, but can't really vouch for it.)
In the beginning
"Let there be a planet with a hothouse effect, so that they can see what happens, as a warning."
"That is rather subtle, God", said the Archangel.
"Well, let it be the planet closest to them. That should do it. They're intelligent after all."
"If you say so."