Semantic search
The Jones Brothers
The two Jones brothers never got along, but both were too stubborn to leave the family estate. They built out two entrances to the estate, one from the south, near Jefferson Avenue, and the newer, bigger one, closer to the historic downtown, and each brother chose to use one of the entrances exclusively, in order to avoid the other and their family. To the confusion of the local folk (but to the open enjoyment of the high school's grammar teacher, who was, surprisingly for his role, a descriptivist), they named the western gate the Jones' gate, and the southern one the Jones's gate, and the brothers earnestly thought that that settled it.
It didn't.
The Future of Knowledge Graphs in a World of Large Language Models
The Knowledge Graph Conference 2023 in New York City invited me for a keynote on May 11, 2023. Given that basically all conversations these days are about large language models, I have given a talk about my understanding on how knowledge graphs and large language models go together.
After the conference, I did a recording of the talk, giving it one more time, in order to improve the quality of the recording. The talk had gotten more than 10,000 views on YouTube so far, which, for me, is totally astonishing.
I forgot to link it here, so here we go finally:
Hot Skull
I watched Hot Skull on Netflix, a Turkish Science Fiction dystopic series. I knew there was only one season, and no further seasons were planned, so I was expecting that the story would be resolved - but alas, I was wrong. And the book the show is based on is only available in Turkish, so I wouldn't know of a way to figure out how the story end.
The premise is that there is a "semantic virus", a disease that makes people 'jabber', to talk without meaning (but syntactically correct), and to be unable to convey or process any meaning anymore (not through words, and very limited through acts). They seem also to loose the ability to participate in most parts of society, but they still take care of eating, notice wounds or if their loved ones are in distress, etc. Jabbering is contagious, if you hear someone jabber, you start jabbering as well, jabberers cannot stop talking, and it quickly became a global pandemic. So they are somehow zombieish, but not entirely, raising questions about them still being human, their rights, etc. The hero of the story is a linguist.
Unfortunately, the story revolves around the (global? national?) institution that tries to bring the pandemic under control, and which has taken over a lot of power (which echoes some of the conspiracy theories of the COVID pandemic), and the fact that this institution is not interested in finding a cure (because going back to the former world would require them to give back the power they gained). The world has slid into economic chaos, e.g. getting chocolate becomes really hard, there seems to be only little international cooperation and transportation going on, but there seems to be enough food (at least in Istanbul, where the story is located). Information about what happened in the rest of the world is rare, but everyone seems affected.
I really enjoyed the very few and rare moments where they explored the semantic virus and what it does to people. Some of them are heart-wrenching, some of them are interesting, and in the end we get indications that there is a yet unknown mystery surrounding the disease. I hope the book at least resolves that, as we will probably never learn how the Netflix show was meant to end. The dystopic parts about a failing society, the whole plot about an "organization taking over the world and secretly fighting a cure", and the resistance to that organization, is tired, not particularly well told, standard dystopic fare.
The story is told very slowly and meanders leisurely. I really like the 'turkishness' shining through in the production: Turkish names, characters eating simit, drinking raki, Istanbul as a (underutilized) background, the respect for elders, this is all very well meshed into the sci-fi story.
No clear recommendation to watch, mostly because the story is unfinished, and there is simply not enough payoff for the lengthy and slow eight episodes. I was curious about the premise, and still would like to know how the story ends, what the authors intended, but it is frustrating that I might never learn.
The right to work
I've been a friend of Universal Basic Income for thirty years, but in the last twenty years, I have growing reservations about it, and many questions. This article about an experiment with a right to work was the first text in a while I read on it that substantially impacted my thinking on this (text is in German). I recommend reading it.
Work is not just a source of money, but for many also a source of meaning, pride, structure, motivation, social connections. Having voluntary access to work seems to be one major component that is necessary on a societal level, in addition to a universal basic income that allows that everyone can live in dignity. Note: I think work should be widely construed. If someone has something that fills that need, that's work. Raising children, taking care of a garden, writing a book, refining piano skills, creating art, taking care of others, taking care of yourself, all these easily count as work in my book.
I wish we were willing and able to experiment with different ways of structuring society as we are willing and able to experiment with technology. We deployed the Internet to the world without worrying about the long term consequences, but we're cautious about giving everyone enough money to not be hungry. That's just broken. I was always disappointed about the fact that sociology and politics as studied and taught by academia were mostly descriptive and not constructive endeavors.
Wikidata - The Making of
Markus Krötzsch, Lydia Pintscher and I wrote a paper on the history of Wikidata. We published it in the History of the Web track at The Web Conference 2023 in Austin, Texas (what used to be called the WWW conference). This spun out of the Ten years of Wikidata post I published here.
The open access paper is available here as HTML: dl.acm.org/doi/fullHtml/10.1145/3543873.3585579
Here as a PDF: dl.acm.org/doi/pdf/10.1145/3543873.3585579
Here on Wikisource, thanks to Mike Peel for reformatting: Wikisource: Wikidata - The Making Of
Here is a YouTube trailer for the talk: youtu.be/YxWs_BS31QE
And here is the full talk (recreated) on YouTube: youtu.be/P3-nklyrDx4
20 years of editing Wikipedia
Today it's been exactly twenty years since I made my first edit to Wikipedia. It was about the island of Brač, in the German Wikipedia.
Here is the version of the article I have created: Brač (as of May 11, 2003)
How much April 1st?
In my previous post, I was stating that I might miss April 1st entirely this year, and not as a joke, but quite literally. Here I am chronicling how that worked out. We were flying flight NZ7 from San Francisco to Auckland, starting on March 31st and landing on April 2nd, and here we look into far too much detail to see how much time the plane spent in April 1st during that 12 hours 46 minutes flight. There’s a map below to roughly follow the trip.
5:45 UTC / 22:45 31/3 local time / 37.62° N, 122.38° W / PDT / UTC-7
The flight started with taxiing for more than half an hour. We left the gate at 22:14 PDT time (doesn’t bode well), and liftoff was at 22:45 PDT.. So we had only about an hour of March left at local time. We were soon over the Pacific Ocean, as we would stay for basically the whole flight. Our starting point still had 1 hour 15 minutes left of March 31st, whereas our destination at this time was at 18:45 NZDT on April 1st, so still had 5 hours 15 minutes to go until April 2nd. Amusingly this would also be the night New Zealand switches from daylight saving time (NZDT) to standard time (NZST). Not the other way around, because the seasons are opposite in the southern hemisphere.
6:00 UTC / 23:00 31/3 local time / 37° N, 124° W / PDT / UTC-7
We are still well in the PDT / UTC-7 time zone, which, in general, goes to 127.5° W, so the local time is 23:00 PDT. We keep flying southwest.
6:27 UTC / 22:27 31/3 local time? / 34.7° N, 127.5° W / AKDT? / UTC-8?
About half an hour later, we reach the time zone border, moving out of PDT to AKDT, Alaska Daylight Time, but since Alaska is far away it is unclear whether daylight saving applies here. Also, at this point we are 200 miles (320 km) out on the water, and thus well out of the territorial waters of the US, which go for 12 nautical miles (that is, 14 miles or 22 km), so maybe the daylight saving time in Alaska does not apply and we are in international waters? One way or the other, we moved back in local time: it is suddenly either 22:27pm AKDT or even 21:27 UTC-9, depending on whether daylight saving time applies or not. For now, April 1 was pushed further back.
7:00 UTC / 23:00 31/3 local time? / 31.8° N, 131.3 W / AKDT? / UTC-8?
Half an hour later and midnight has reached San Francisco, and April 1st has started there. We were more than 600 miles or 1000 kilometers away from San Francisco, and in local time either at 23:00 AKDT or 22:00 UTC-9. We are still in March, and from here all the way to the Equator and then some, UTC-9 stretched to 142.5° W. We are continuing southwest.
8:00 UTC / 23:00 31/3 local time / 25.2° N, 136.8° W / GAMT / UTC-9
We are halfway between Hawaii and California. If we are indeed in AKDT, it would be midnight - but given that we are so far south, far closer to Hawaii, which does not have daylight saving time, and deep in international waters anyway, it is quite safe to assume that we really are in UTC-9. So local time is 23:00 UTC-9.
9:00 UTC / 0:00 4/1 local time / 17.7° N, 140.9° W / GAMT / UTC-9
There is no denying it, we are still more than a degree away from the safety of UTC-10, the Hawaiian time zone. It is midnight in our local time zone. We are in April 1st. Our plan has failed. But how long would we stay here?
9:32 UTC / 23:32 31/3 local time / 13.8° N, 142.5° W / HST / UTC-10
We have been in April 1st for 32 minutes. Now we cross from UTC-9 to UTC-10. We jump back from April to March, and it is now 23:32 local time. The 45 minutes of delayed take-off would have easily covered for this half hour of April 1st so far. The next goal is to move from UTC-10, but the border of UTC-10 is a bit irregular between Hawaii, Kiribati, and French Polynesia, looking like a hammerhead. In 1994, Kiribati pushed the Line Islands a day forward, in order to be able to claim to be the first ones into the new millennium.
10:00 UTC / 0:00 4/1 local time / 10° N, 144° W / HST / UTC-10
We are pretty deep in HST / UTC-10. It is again midnight local time, and again April 1st starts. How long will we stay there now? For the next two hours, the world will be in three different dates: in UTC-11, for example American Samoa, it is still March 31st. Here in UTC-10 it is April 1st, as it is in most of the world, from New Zealand to California, from Japan to Chile. But in UTC+14, on the Line Islands, 900 miles southwest, it is already April 2nd.
11:00 UTC / 1:00 4/1 local time / 3° N, 148° W / HST / UTC-10
We are somewhere east of the Line Islands. It is now midnight in New Zealand and April 1st has ended there. Even without the delayed start, we would now be solidly in April 1st local time.
11:24 UTC / 1:24 4/1 local time / 0° N, 150° W / HST / UTC-10
We just crossed the equator.
12:00 UTC / 2:00 4/2 local time / 3.7° S, 152.3° W / LINT / UTC+14
The international date line in this region does not go directly north-south, but goes one an angle, so without further calculation it is difficult to exactly say when we crossed the international date line, but it would be very close to this time. So we just went from 2am local time in HST / UTC-10 on April 1st to 2am local time in LINT / UTC+14 on April 2nd! This time, we have been in April 1st for a full two hours.
(Not for the first time, I wish Wikifunctions would already exist. I am pretty sure that taking a geocoordinate and returning the respective timezone will be a function that will be available there. There are a number of APIs out there, but none of which seem to provide a Web interface, and they all seem to require a key.)
12:44 UTC / 2:44 4/1 local time / 8° S, 156° W / HST / UTC-10
We just crossed the international date line again! Back from Line Island Time we move to French Polynesia, back from UTC+14 to UTC-10 again - which means it switches from 2:44 on April 2nd back to 2:44 on April 1st! For the third time, we go to April 1st - but for the first time we don’t enter it from March 31st, but from April 2nd! We just traveled back in time by a full day.
13:00 UTC / 3:00 4/1 local time / 9.6° S, 157.5° W / HST / UTC-10
We are passing between the Cook Islands and French Polynesia. In New Zealand, daylight saving time ends, and it switches from 3:00 local time in NZDT / UTC+13 to 2:00 local time in NZST / UTC+12. While we keep flying through the time zones, New Zealand declares itself to a different time zone.
14:00 UTC / 4:00 4/1 local time / 15.6° S, 164.5° W / HST / UTC-10
We are now “close” to the Cook Islands, which are associated with New Zealand. Unlike New Zealand, the Cook Islands do not observe daylight saving time, so at least one thing we don’t have to worry about. I find it surprising that the Cook Islands are not in UTC+14 but in UTC-10, considering they are in association with New Zealand. On the other side, making that flip would mean they would literally lose a day. Hmm. That could be one way to avoid an April 1st!
14:27 UTC / 3:27 4/1 local time / 18° S, 167° W / SST / UTC-11
We move from UTC-10 to UTC-11, from 4:27 back to 3:27am, from Cook Island Time to Samoa Standard Time. Which, by the way, is not the time zone in the independent state of Samoa, as they switched to UTC+13 in 2011. Also, all the maps on the UTC articles in Wikipedia (e.g. UTC-12) are out of date, because their maps are from 2008, not reflecting the change of Samoa.
15:00 UTC / 4:00 4/1 local time / 21.3° S, 170.3° W / SST / UTC-11
We are south of Niue and east of Tonga, still east of the international date line, in UTC-11. It is 4am local time (again, just as it was an hour ago). We will not make it to UTC-12, because there is no UTC-12 on these latitudes. The interesting thing about UTC-12 is that, even though no one lives in it, it is relevant for academics all around the world as it is the latest time zone, also called Anywhere-on-Earth, and thus relevant for paper submission deadlines.
15:23 UTC / 3:23 4/2 local time / 23.5° S, 172.5° W / NZST / UTC+12
We crossed the international date line again, for the third and final time for this trip! Which means we move from 4:23 am on April 1st local time in Samoa Standard Time to 3:23 am on April 2nd local time in NZST (New Zealand Standard Time). We have now reached our destination time zone.
16:34 UTC / 4:34 4/2 local time / 30° S, 180° W / NSZT / UTC+12
We just crossed from the Western into the Eastern Hemisphere. We are about halfway between New Zealand and Fiji.
17:54 UTC / 5:52 4/2 local time / 37° S, 174.8°W / NZST / UTC+12
We arrived in Auckland. It is 5:54 in the morning, on April 2nd. Back in San Francisco, it is 10:54 in the morning, on April 1st.
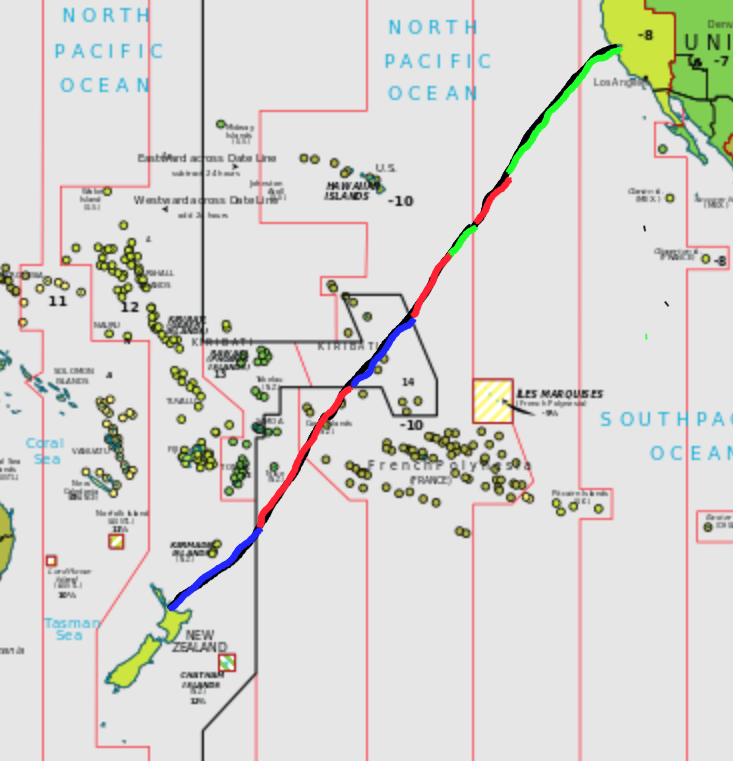
Green is March 31st, Red April 1st, Blue April 2nd, local times during the flight.
Basemap https://commons.wikimedia.org/wiki/File:Standard_time_zones_of_the_world_%282012%29_-_Pacific_Centered.svg CC-BY-SA by TimeZonesBoy, based on PD by CIA World Fact Book
{kind=link}
Postscript
Altogether, there was not one April 1st, but three stretches of April 1st: first, for 32 minutes before returning to March 31st, then for 2 hours again, then we switched to April 2nd for 44 minutes and returned to April 1st for a final 2 hours and 39 minutes. If I understand it correctly, and I might well not, as thinking about this causes a knot in my brain, the first stretch would have been avoidable with a timely start, the second could have been much shorter, but the third one would only be avoidable with a different and longer flight route, in order to stay West of the international time line, going south around Samoa.
In total, we spent 5 hours and 11 minutes in April 1st, in three separate stretches. Unless Alaskan daylight saving counts in the Northern Pacific, in which case it would be an hour more.
So, I might not have skipped April 1st entirely this year, but me and the other folks on the plane might well have had the shortest April 1st of anyone on the planet this year.
I totally geeked out on this essay. If you find errors, I would really appreciate corrections. Either in Mastodon, mas.to/@vrandecic, or on Twitter, @vrandecic. Email is the last resort, vrandecic@gmail.com (The map though is just a quick sketch)
One thing I was reminded of is, as Douglas Adams correctly stated, that writing about time travel really messes up your grammar.
The source for the flight data is here:
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA/tracklog
No April Fool's day
This year, I am going to skip April Fool's day.
I am not being glib, but quite literal.
We are taking flight NZ7 starting on the evening of March 31 in San Francisco, flying over the Pacific Ocean, and will arrive on April 2 in the early morning in Auckland, New Zealand.
Even if one actually follows the flight route and overlays it over the timezone map, it looks very much like we are not going to spend more than a few dozen minutes, or at most a few hours, in April 1, if all goes according to plan.
Looking forward to it!
Here's the flight data of a previous NZ7 flight, from Sunday: https://flightaware.com/live/flight/ANZ7/history/20230327/0410Z/KSFO/NZAA/tracklog
Here are the timezones (but it's Northern winter time). Would be nice to overlay the two maps: 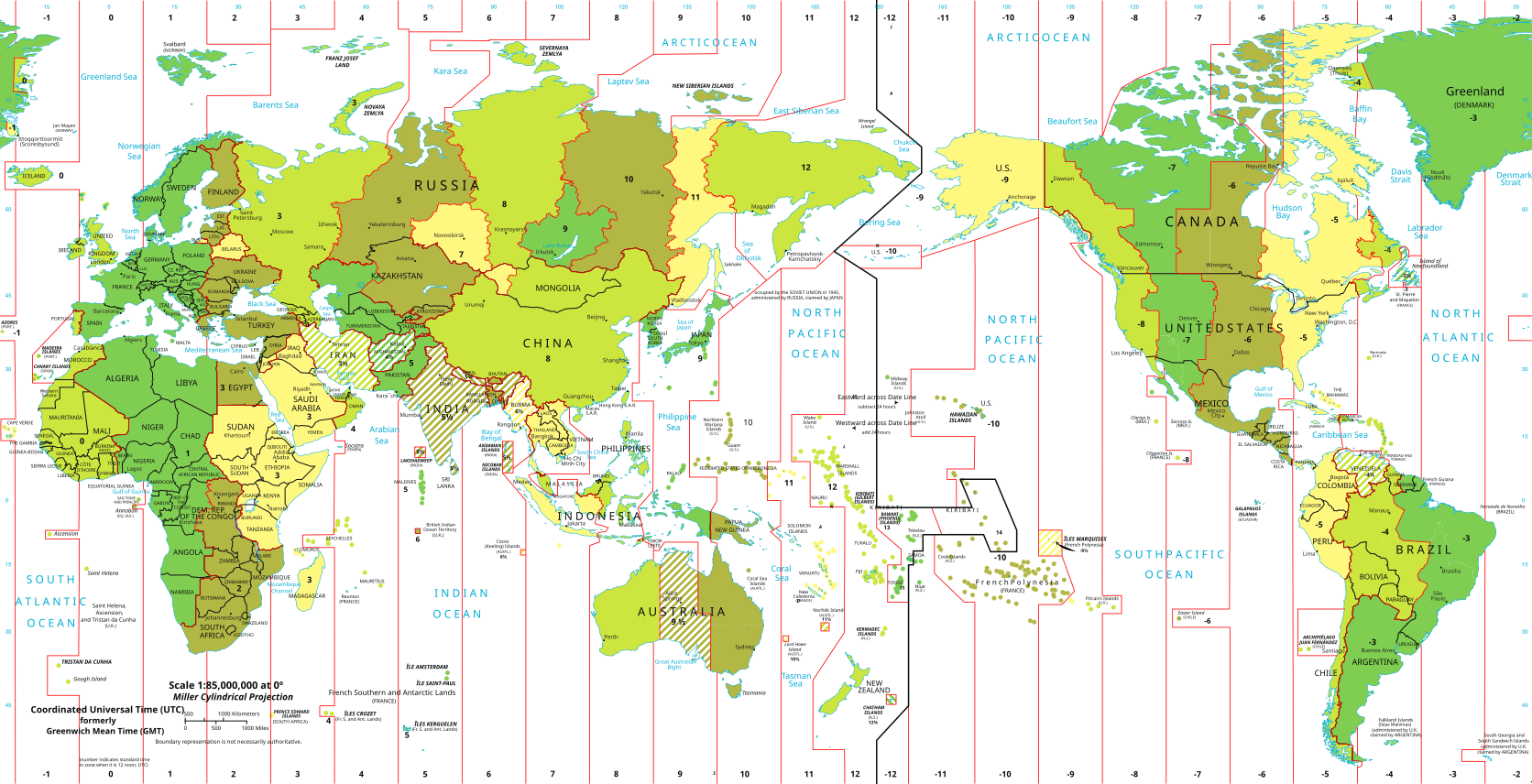
Where's Wikifunctions when it's needed?
The question seems to be twofold: how often do we cross the dateline, and how close are we to local time midnight while crossing the dateline. For a perfect date miss one would need to cross the dateline exactly once, at a 24 hour difference, as close as possible to local midnight.
Gordon Moore (1929-2023)
Gordon Moore was not only the co-founder of Intel and the namesake for Moore's law, the claim that every two years the number of components on a chip would double, he was also, together with his wife Betty Moore, one of the generous donors who made Wikidata possible. Gordon and Betty Moore were known for their philanthropy, and it is easy to find their names engraved at the universities, zoos, museums, and galleries in the Bay Area. Gordon Moore died today at the age of 94.
Thank you for enabling us to make Wikidata happen.
Last Unicorn dreamcast
One thing my sister and I were doing from time to time was to think, if the Last Unicorn was remade as a live action movie, who would we cast in the different roles? It is sad to see how many of our dreamcast have since died: our favorite Prince Lir was Heath Ledger, and King Haggard, unsurprisingly, Christopher Lee.
Since I was reading the book with Little One, and now watched the movie again (for the 120th time or so), I was again going through my current dreamcast. Here we go.
- Lady Amalthea - Anna Taylor-Joy
- Schmendrick - Zach Braff, Donald Glover
- Molly Grue - Mia Farrow
- Prince Lir - Owen Wilson, no, getting too old; Liam Hemsworth? Chloe Moretz would be an interesting choice
- King Haggard - Anthony Hopkins, Jack Nicholson
Since it is en vogue, I also asked Bard and ChatGPT. Here's Bard:
- Jeff Bridges as Schmendrick the Magician
- Mia Farrow as Molly Grue
- Angela Lansbury as the Unicorn
- Daryl Hannah as Filidor
- Jeff Goldblum as Schmendrick's sidekick, Bungle
- Peter Dinklage as the Red Bull
- Uma Thurman as Mommy Fortuna
- Alan Rickman as King Haggard
OK, Alan Rickman is a great choice, but unfortunately dead. Uma Thurman as Mommy Fortuna is weird. Peter Dinklage as the Red Bull... why does the Red Bull need to be cast at all? Who are Bungle and Filidor? Angela Lansbury as the Unicorn / Lady Amalthea is... not the right choice. Also dead. Mia Farrow and Jeff Bridges are too obvious choices given their roles in the cast of the animation movie, also Angela Lansbury is from the original cast. I would give Bard a D for that answer.
ChatGPT says:
- Unicorn - Saoirse Ronan or Emma Watson
- Schmendrick - Timothee Chalamet or Eddie Redmayne
- Molly Grue - Meryl Streep or Helen Mirren
- King Haggard - Ian McKellen or Christopher Lee (if he were still alive)
- Prince Lir - Tom Holland or Ansel Elgort
- Mommy Fortuna - Tilda Swinton or Cate Blanchett
Not even close to my choice, but heck, those are good choices. Molly Grue and Mommy Fortuna seem both a bit over-cast. Prince Lir and Schmendrick are pretty brilliant choices. I am not particularly impressed by Emma Watson for Lady Amalthea, I could see Saoirse Ronan work.
I'd give a B+ to ChatGPT.
I feel like ChatGPT seems to go for actors and actresses that are popular with the crowd who likes The Last Unicorn? Not the worst choice.
I followed up with Bard to see who Bungle and Filidor are, because they don't appear neither in the book nor in the movie, if I remember correctly. So, "Bungle is a red unicorn who is Schmendrick's sidekick in the novel The Last Unicorn. He is a clumsy and incompetent unicorn, but he is also a loyal and brave friend. Bungle is played by Jeff Goldblum in the 1982 animated film adaptation of the novel." And "Filidor is a bard in the novel The Last Unicorn. He is a wandering minstrel who travels the land singing songs and telling stories. Filidor is a wise and kind-hearted man, and he is always willing to help those in need. He is played by Daryl Hannah in the 1982 animated film adaptation of the novel." That's entirely a fabrication.
Running out of text
Many of the available text corpora have by now been used for training language models. One untapped corpus so far have been our private messages and emails.
How fortunate that none of the companies that train large language models have access to humongous logs of private chats and emails, often larger than any other corpus for many languages.
How fortunate that those who do have well working ethic boards established, who would make sure that such requests are evaluated.
How fortunate that we have laws in place to protect our privacy.
How fortunate that when new models are published also the corpora are being published on which the models are being trained.
What? Your telling me, "Open"AI is keeping the training corpus for GPT-4 secret? The company closely associated with Microsoft, who own Skype, Office, Hotmail? The same Microsoft who just fired an ethics team? Why would all that be worrisome?
P.S.: To make it clear: I don't think that OpenAI has used private chat logs and emails as training data for GPT-4. But by not disclosing their corpora, they might be checking if they can get away with not being transparent, so that maybe next time they might do it. No one would know, right? And no one would stop them. And hey, if it improves the metrics...
Oscar winning families
Yesterday, when Jamie Lee Curtis won her Academy Award, I learned that both her parents were also nominated for Academy Awards. Which lead to the question: who else?
I asked Wikidata, which lists four others:
- Laura Dern
- Liza Minnelli
- Nora Ephron
- Sean Astin
Only one of them belongs to the even more exclusive club of people who won an Academy Award, and where both parents also did: Liza Minnelli, daughter of Vincente Minelli and Judy Garland.
Also interesting: List of Academy Award-winning families
The place of birth of Ena Begović
I stumbled accidentally over a discrepancy regarding the place of birth of the Croatian actress Ena Begović, and noticed that if you ask Google for the place of birth, it answers Trpanj, whereas Wikipedia lists Split. I was curious where Google got Trpanj from, and how to fix it (especially now that I am not at Google anymore).
The original article in English Wikipedia was created in August 2005 by Raoul DMR. The article listed her as a "native of Split", which in September 2005 was turned into "born in Split".
In April 2018, Lole484, a user who gets blocked for sockpuppeting later, adds that she was born in "Trpanj near Split". There is no Trpanj near Split, but there is a Trpanj on Pelješac. Realzing that, they remove the "near Split" part. In 2019, Ivan Ladic - a sockpuppet of Lole484 - adds a reference to the city of birth being Trpanj, Večernji list, a well known Croatian news magazine.
In April 2020, an anonymous editor changes the place of birth back to Split, and adds a reference to the Croatian national encyclopedia. Today, I changed it back to Trpanj, accidentally while not being logged in (thus anonymously), to possibly encourage a discussion, after starting a conversation on the talk page on English and Croatian a few weeks ago that had one reply.
Interestingly, within a minute after changing the text, I went to Google and asked again for the date of birth, and Google again shows me Trpanj - but this time with the Wikipedia article and the updated snippet as a source. That is impressive.
When I asked Bing, Bing was saying Split for the last three weeks, since I started this adventure, whenever I checked. Today, it still kept saying Split, referencing two sources, one of them English Wikipedia, although I had already changed English Wikipedia. Not as fresh. Let's see how long this will stick. (Maybe folks at Bing should also talk with my colleagues at Wikimedia Enterprise to improve their freshness?)
The Croatian article was created in 2006 after the English one already stated Split, and Split was presumably copied over from the English version. Lole484 changed it to Trpanj in May 2018, and was later also blocked on Croatian Wikipedia, for unrelated reasons of vandalism. The same anonymous editor as on English Wikipedia changes it back to Split in April 2020.
Serbian and Serbocroatian started their articles in 2007, Russian in 2012, Ukrainian in 2016, Albanian and Bulgarian in 2017, Egyptian Arabic was created in October 2020. They all had Split from the beginning and throughout until today, presumably copied from English, directly or indirectly.
Amusingly, Serbian Wikipedia's opening sentence, which includes the place of birth being Split, receives a reference in January 2022 - but the reference actually states Trpanj.
None of the other language editions had their article started in the 2018-2019 window when English and Croatian stated the place of birth as Trpanj.
The only other Wikipedia language edition that saw a change of the place of birth was the Bosnian. The article on Bosnian Wikipedia started a few months after the Croatian, in 2006 (and thus being the third oldest article), and presumably also just copied from either Croatian or English. Lole484 changed it to Trpanj in April 2018, just like on the other Wikipedias. Here it was reverted the next day, but Lole484's sockpuppet Ivan Ladic reinstated that change in January 2019. When I started this adventure, the only Wikipedia that stated Trpanj was Bosnian, all other eight language editions with an article said Split.
On Wikidata, the item was created in 2012, shortly after the launch of the site, based on the existing six sitelinks. The place of birth being Split is added the following year, imported from the Russian Wikipedia.
After I stumbled upon the situation, I added Trpanj as second place of birth, and added sources to both Trpanj and Split.
What's the situation outside of Wikipedia? Both places have pretty solid references going for them:
Trpanj
- Večernji list, article from 2016
- Biografija stated Trpanj, no date, but after 2013 (Archive has the first copy from October 2020)
- tportal.hr has an article on a photography exhibition in Trpanj about Ena Begović, saying the place is chosen because it is her place of birth, published 2016
- Jutarnji list, a well known Croatian newspaper, has a long article about the actress, calling their house in Trpanj the 'rodna kuća', their birth home, of Ena and her sister Mia. This does not necessarily mean that it is literally the house they were born in. Published 2010
- HRT (Croatian national broadcaster), published 2021
- Dubrovački Vjesnik, local newspaper close to Trpanj, lists Trpanj, article from 2020
- Slobodna Dalmacija, a local newspaper from Split, writes Trpanj (but note that this is the same author as the previous article)
- Juarnji list, published 2020 (but note that this is the same author as the previous article)
- Geni.com says Trpanj, last updated 2022
Split
- Croatian national encyclopedia, published in 2021
- Filmski leksikon from the same publisher, no date, but after 2008 (Archive has the first copy from 2022)
- Proleksis, but same publisher as above, as of 2013
- Gloria, a Croatian magazine, says she was born in Split, but Trpanj was her home, published 2020
- film.hr via Archive, from 2007
- Espreso.co.rs writes Split, published 2022
- Find-a-grave lists Split on the site, but more importantly, the photograph of her grave avoids a mention of the place, but only gives the date of her birth and death
- ČSFD (Czechoslovak film database)
- Prabook, from the World Biographical Encyclopedia
- Svensk Filmdatabas
- TMDB (The Movie Database)
- Discogs
24sata says she grew up in Trpanj, gives her date of birth, but avoids stating her place of birth.
Only very few of the sources predate the English Wikipedia article, most notably:
- net.hr published the news of her death and burial in 2000, and lists Split as the place of birth
- IMdb from April 2005 via Archive lists Split, and throughout (I guess?) until today
I also looked up her sister Mia and found her profile on Facebook and sent her a message, but I assume she never even saw this message request. At least I never received an answer (and I didn't expect to). For Mia, the situation is similar: her article originally stated Split, was changed by Lole484 and reverted by an anonymous user, both in English and Croatian, whereas the other languages just list Split throughout.
There were many other sources, and they were going one way or the other. Many of the sources probably just copied from each other. The fact that there were some sources, such as Večernji, that stated Trpanj before it ever made to Wikipedia, but after Split was listed in Wikipedia, was swaying me to think it is Trpanj. Also, it was not always the strongest sources (e.g. usually I would rank the national encyclopedia over Večernji) that said Trpanj, but it was the most in-depth articles, that looked like the authors actually took the time to do some research. Many of the sources looked like they were just bots copying from Wikipedia or Wikidata, or quick pieces taking the base data from Wikipedia.
But then, finally, I stumbled upon one more source: index.hr re-published in 2019 an 1989 interview by Kemal Mujičić with Ena and Mia Begović. Here's a quote from the interview:
Rođene su u Trpnju na Pelješcu.
Ena: Molim vas, to posebno naglasite: Svi misle da smo Dubrovkinje.
Mia: Zanimljivo je da smo u Trpnju rođene kao podstanarke. Roditelji su tek poslije sagradili onu kućicu.
Translation:
They (Ena and Mia) are born in Trpanj on Pelješac.
Ena: Please put an emphasis on this: everyone thinks we are from Dubrovnik.
Mia: It is interesting that in Trpanj we were born as renters. Our parents built the little house (in which we lived) only later.
Ha! It is amusing to see that Ena's worry was that everyone thinks they are from Dubrovnik. I couldn't find a single source claiming that (but she went to high school (gimnazijum) in Dubrovnik, which is probably the source of that statement from 30 years ago). Also, so much for birth house.
Given all of that, I am going with Trpanj, and making the changes to the Wikipedia languages as much as I can (if someone can help with Arabic and Egyptian Arabic for Ena and Mia, that would be swell, I cannot edit that language edition). Let's see if it sticks.
So, why did Google know the correct answer, even though their usual sources, such as Wikidata and Wikipedia where saying Split? I mustn't say too much but it is due to the Google Knowledge Graph team and their quality processes. Seriously, congratulations to my former colleagues at Google for getting that right!
Just for fun, I also asked ChatGPT (on February 15). And the answer surprised me: when I asked in English, it gave me, unsurprisingly, Split (certainly what the Web seems to believe). But when I asked in Croatian, it gave me a different answer! And the answer was neither Split, nor Trpanj, and also not Dubrovnik - but Zagreb! It is interesting that something like the place of birth of an actress would lead to different answers depending on the language. I would have expected this knowledge to be in the 'world knowledge' of the LLM, not in the 'language knowledge'. I can't check out Bing's chat interface, as I have no access to it, but I would be curious what it says and how long it takes to update.
Thank you for going along on this rather nerdy ride of citogenesis.
Update
Ah, only a few hours after this publication, Bing got updated. And they not only switched from Split to Trpanj, they use this very blogpost as one of the two authoritative references for Trpanj!
Ina Kramer (1948-2023)
1990 erschien die erste aventurische Regionalkarte "im 3D Effekt", wie es damals beworben wurde, "Das Bornland" im Abenteuer "Stromaufwärts" von Michelle Schwefel. Später im Jahr erschien dann die Spielhilfe "Das Königreich am Yaquir", in dem die Karte zum Lieblichen Feld war.
Ich habe stundenlang diese Karten angestarrt. Sie waren so unglaublich detailliert. So wunderschön. Ich war sprachlos, wie schön diese Karten waren. Ich kannte nichts was die Qualität dieser Karten hatte, nicht nur bezüglich Karten für Rollenspielwelten und Fantasywelten, sondern überhaupt.
Es war ein frecher Traum, sich vorzustellen, ganz Aventurien in diesem Format, eins zu einer million, zu haben, und dennoch, innerhalb eines guten Jahrzehnts war der Traum erfüllt, Box für Box, Publikation für Publikation.
Wir verdanken dieses Meisterwerk, Aventurien im Massstab von 1:1.000.000, der Autorin und Grafikerin Ina Kramer. Ina's Bilder und vor allem Porträts und Karten in den DSA Publikationen der späten 80er und den 90er haben für mich mein Bild von DSA und wie ich mir Aventurien vorstellte geprägt wie sonst nur Caryad. Ob das Porträt von Kaiser Hal, Haldana von Ilmenstein, Prinz Brin, so viele andere. Neben ihren Bildern schrieb sie auch vielerlei Texte, vor allem Romane.
Das Rad ist zerbrochen. Am 10. Februar 2023 ist Ina Kramer im Alter von 74 Jahren gestorben.
Ina, vielen Dank für Deine Werke. Ich durfte Ina ein paar Mal treffen, auf Konventen und manchen anderen Gelegenheiten. Ihre Werke haben für mich einen wichtigen Teil meines Lebens mit Bildern und Karten erfüllt. Ich glaube auch, dass Inas Karten mein lebenslanges Interesse an Landkarten weckte.
Connectionism and symbolism: The fall of the symbolists
The big tech layoffs happen, unfortunately and entirely by coincidence, at a time of incredibly elevated expectations regarding machine learned generative models: ChatGPT may not be the 'best' language model out there, but due to the hard work by OpenAI to turn it into an easy to use product, and the huge amount of resources made available for free so that a very large audience could play with it, has in a very short time managed to captured the imagination of many and the conversation. I would say, rightfully. The way ChatGPT was released led to a shock in the sense that we are right now dazed and confused about what effect this technology will have on the world.
And while we are still in the middle of processing this shock, large scale strategic decisions regarding many projects and people were made. Anyone in big tech who worked on symbolic approaches in natural language processing, knowledge representation and reasoning, and other fields of artificial intelligence had a hard time to keep their job. It feels right now like large language models will make all of these symbolic approaches superfluous (I think, this might be true, but is more likely to turn out to be mistaken).
It is always difficult to predict how events will be viewed historically. The advent of wide-spread deep learning approaches in the 2010s, culminating in the well-deserved recognition of Hinton, LeCun, and Bengio with the Turing Award show clearly what dominated the research agenda and the attention in AI in the last decade. But until now it felt like symbolic approaches still had some space left, that the growth in deep learning was in addition to other approaches. Symbolic approaches were ready to offer impulses and work on ideas for a field which might well be climbing towards a local maximum.
But a good number of the teams that were disbanded in the layoffs were exactly teams working with such symbolic approaches, and it feels like these parts of AI are now entering a bitter-cold winter.
A lot of knowledge is being lost right now, and many paths to innovative ideas are being buried. I have no doubt that there are still a lot of breakthroughs to be had in machine learning, and that there is immense value to be collected from the research results in machine learning from the last few years. And with immense I mean tens and hundreds of billions of dollars.
Nevertheless I expect that we will hit a wall. Reach a local maximum. Run into problems and limitations. And it would be good to keep a wider net to cast. To keep a larger search space alive. Alas, it seems it is not meant to be. In this abundance of capital and potential value, we seem to be on the way to starve research, optimise away alternatives, and to give everything to the mainstream ideas.
22 years of Wikipedia
I was just reading a long discussion regarding the differences between Open Street Maps and Wikipedia / Wikidata, and one of the mappers complained "Wiki* cares less about accuracy than the fact that there is something that can be cited", and calling Wikipedia / Wikidata contributions "armchair work" because we don't go out into the world to check a fact, but rely on references.
I understand the expressed frustration, but at the same time I'm having a hard time letting go of "reliability not truth" being a pillar of Wikipedia.
But this makes Wikipedia an inherently conservative project, because we don't reflect a change in the world or in our perception directly, but have to wait for reliable sources to put it in the record. There's something I was deeply uncomfortable with: so much of my life is devoted to a conservative project?
Wikipedia is a conservative project, but at the same time it's a revolutionary project. Making knowledge free and making knowledge production participatory is politically and socially a revolutionary act. How can this seeming contradiction be brought to a higher level of synthesis?
In the last few years, my discomfort with the idea of Wikipedia being conservative has considerably dissipated. One might think, sure, that happened because I'm getting older, and as we get older, we get more conservative (there's, by the way, unfortunate data questioning this premise: maybe the conservative ones simply live longer because of inequalities). Maybe. But I like to think that the meaning of the word "conservative" has changed. When I was young, the word conservative referred to right wing politicians who aimed to preserve the values and institutions of their days. An increasingly influential part of todays right wing though has turned into a movement that does not conserve and preserve values such as democracy, the environment, equality, freedoms, the scientific method. This is why I'm more comfortable with Wikipedia's conservative aspects than I used to be.
But at the same time, that can lead to a problematic stasis. We need to acknowledge that the sources and references Wikipedia has been built on, are biased due to historic and ongoing inequalities in the world, due to different values regarding the importance of certain types of references in the world. If we truly believe that Wikipedia aims to provide everyone with access to the sum of all human knowledge, we have to continue the conversations that have started about oral histories, about traditional knowledges, beyond the confines of academic publications. We have to continue and put this conversation and evolution further into the center of the movement.
Happy Birthday, Wikipedia! 22 years, while I'm 44 - half of my life (although I haven't joined until two years later). For an entire generation the world has always been a world with free knowledge that everyone can contribute to. I hope there is no going back from that achievement. But just as democracy and freedom, this is not a value that is automatically part of our world. It is a vision that has to be lived, that has to be defended, that has to be rediscovered and regained again and again, refined and redefined. We (the collective we) must wrest it from the gatekeepers of the past (including me) to allow it to remain a living, breathing, evolving, ever changing project, in order to not see only another twenty two years, but for us to understand this project as merely a foundation that will accompany us for centuries.
Good bye, kuna!
Now that the Croatian currency has died, they all come to the Gates of Heaven.
First goes the five kuna bill, and Saint Peter says "Come in, you're welcome!"
Then the ten kuna bill. "Come in, you're welcome!"
So does the twenty and fifty kuna bills. "Come in, you're welcome!"
Then comes the hundred kuna bill, expecting to walk in. Saint Peter looks up. "Where do you think you're going?"
"Well, to heaven!"
"No, not you. I've never seen you in mass."
(My brother sent me the joke)
Happy New Year, 2023!
For starting 2023, I will join the Bring Back Blogging challenge. The goal is to write three posts in January 2023.
Since I have been blogging on and off the last few years anyway, that shouldn't be too hard.
Another thing this year should bring is to launch Wikifunctions, the project I have been working on since 2020. It was a longer ride than initially hoped for, but here we are, closer to launch than ever. The Beta is available online, and even though not everything works yet, I was already able to impress my kid with the function to reverse a text.
Looking forward to this New Year 2023, a number that to me still sounds like it is from a science fiction novel.
Goal for Wikidata lexicographic data coverage 2023
At the beginning of 2022, Wikidata had 807 Croatian word forms, covering 5.8% of a Croatian language corpus (Croatian Wikipedia). One of my goals this year was to significantly increase the coverage, trying to add word forms to Wikidata from week to week. And together with a yet small number of contributors, we pushed coverage just in time for the end fo the year to 40%. With only 3,124 forms, we covered 40% of all occurrences of words in the Croatian Wikipedia, i.e. 11.4 Million word occurrences (tokens).
Since every percent is more and more difficult to add, for next year I aim for us to reach 60% coverage, or 5.7 Million more word occurrences. Below's a list of most frequent words in the corpus that are still missing. Let's see how many forms will be covered by the end of 2023! I think that's ambitious, even though it is, in coverage term only half of what we achieved this year. But as said, every subsequent percentage will become more difficult than the previous one.
Statistics and missing words for 55 languages: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage
Current statistics for Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Statistics
Statistics as of end of year 2022: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1797161415
Statistics for end of year 2021: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1551737937
List of most frequent missing forms in Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Missing
Using ChatGPT for fact checking
I wanted to explore the idea that we could use ChatGPT for fact checking. So I took a random article - it gave me the article on Jewish Ideas Daily, copied the text into ChatGPT with the following prompt:
Here's the text of a Wikipedia article. Please find the three statements that are most likely incorrect and rank them, in order to guide fact checking:
Followed by the Wikipedia article text. Here's the answer:
- "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." This statement is incorrect because according to the article, Margot Lurie was the editor of Jewish Ideas Daily "until December 2012."
- "Jewish Ideas Daily drew notice for controversial features including one accusing Christopher Hitchens of antisemitism." This statement is difficult to verify without more context, as it is not clear when this feature was published or what specifically it accused Hitchens of.
- "Like Jewish Review of Books, and Jewish Ideas Daily, Mosaic is funded by the Tikvah Fund." This statement is incorrect because according to the article, Mosaic succeeded Jewish Ideas Daily in June 2013 and is therefore not funded by the Tikvah Fund in the same way as Jewish Ideas Daily and Jewish Review of Books.
Regarding the first statement, GPT says that the sentence "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." is incorrect. I am not disagreeing, but that sentence does not appear in the Wikipedia article text.
Regarding the second statement, GPT says that there is no reference for that statement. In fact, there is, and Wikipedia provides it.
Regarding the third statement, I didn't check the statement, but the argumentation for why it should be checked is unconvincing: if Tikvah fund financed Jewish Ideas Daily, why would it not finance the successor Mosaic? It would be good to add a reference for these statements, but that's not the suggestion.
In short: the review by ChatGPT looks really good, but the suggestions in this case were not good.
The exercise was helpful insofar the article infobox and the text were disagreeing on the founding of the newspaper. I fixed that, but that's nothing ChatGPT pointed out (and couldn't, as I didn't copy and paste the infobox).